武汉大学软件工程操作系统课程设计
主要是使用高级语言模拟操作系统管理的一些算法,整体难度不大,甚至感觉像是在做数据结构的作业。
第一次实验课写了两个实验,分别是
1,模拟处理器调度算法中的按优先数调度算法
2,模拟可变分区管理方式下采用首次适应算法实现主存分配和回收
实验要求如下:
*(1)假定系统有5个进程,每个进程用一个PCB来代表。PCB的结构为:*
*·进程名——如P1~P5。*
*·指针——按优先数的大小把5个进程连成队列,用指针指出下一个进程PCB的首地址。*
*·要求运行时间——假设进程需要运行的单位时间数。*
*·优先数——赋予进程的优先数,调度时总是选取优先数大的进程先执行。*
*·状态——假设两种状态:就绪和结束,用R表示就绪,用E表示结束。初始状态都为就绪状态。*
*(2)* *开始运行之前,为每个进程确定它的“优先数”和“要求运行时间”。通过键盘输入这些参数。*
*(3)* *处理器总是选择队首进程运行。采用动态改变优先数的办法,进程每运行1次,优先数减1,要求运行时间减1。*
*(4)* *进程运行一次后,若要求运行时间不等于0,则将它加入就绪队列,否则,将状态改为“结束”,退出就绪队列。*
*(5)* *若就绪队列为空,结束,否则转到**(3)**重复。*
用java写的,核心算法一个排序
每次执行让进程优先数和运行时间-1,再重新排序,执行优先数最大的进程。
直到所有进程要求运行时间全为0
写的可能不是很规范,建了一个OperationSystem类,在其中定义了一些静态方法,对PCB类进行操作。
运行效果如下:
模拟设置了五个线程,分别让用户输入线程优先数

输入完成后会自动输出表格显示信息,并将第一次按优先数进行排序的表显示出来
然后依次执行,每执行会本次执行的进程的进程名,并将新的表格输出。
输入完成后初始表和排序表:
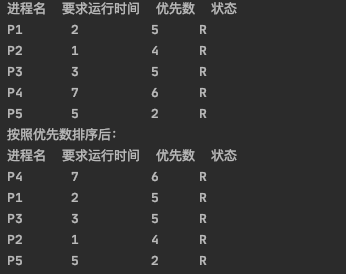
运行过程:
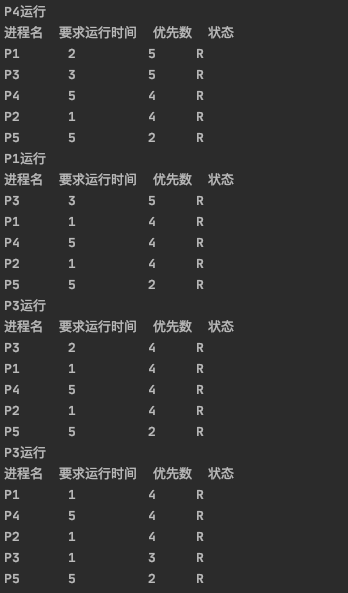
中间过程还是比较长的,最后所有要求运行时间全0,退出:
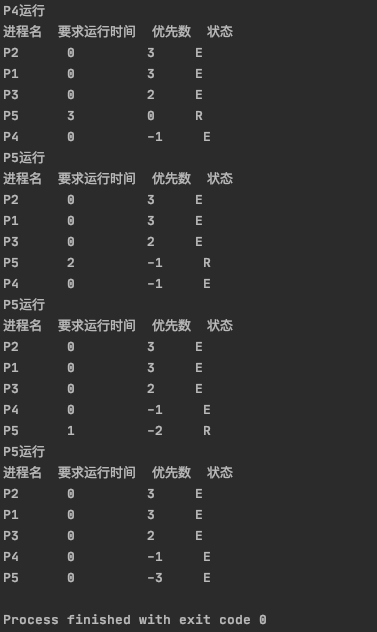
实验要求:
(1) *可变分区方式是按作业需要的主存空间大小来分割分区的。当要装入一个作业时,根据作业需要的主存容量查看是否有足够的空闲空间,若有,则按需分配,否则,作业无法装入。假定内存大小为128K,空闲区说明表格式为:*
*·分区号——表示是第几个空闲分区;*
*·起始地址——指出空闲区的起始地址;*
*·长度——一个连续空闲区的长度;*
(2) *采用首次适应算法分配回收内存空间。运行时,输入一系列分配请求和回收请求。*
*要求能接受来自键盘的空间申请及释放请求,能显示**分区分配及回收后的内存布局情况。*
分配很容易,就是按顺序找到第一个空间大于申请空间的分区,然后分配给他
回收算法如下需要考虑几种情况:
1,回收分区起始地址和空闲分区相邻,但和后面空闲分区不相邻,则将回收分区和前面相邻的合并,起始地址为前面空闲分区起始地址
2,回收分区起始地址和前面空闲分区不相邻,和后面分区相邻,则与后面分区合并,起始地址为回收分区起始地址
3,回收分区和前,后空闲分区都不相邻,则新建一个表项
4,回收分区和前后空闲分区都相邻,则将3块分区合并,其实地址为第一块空闲分区起始地址
运行截图如下:
请求内存:
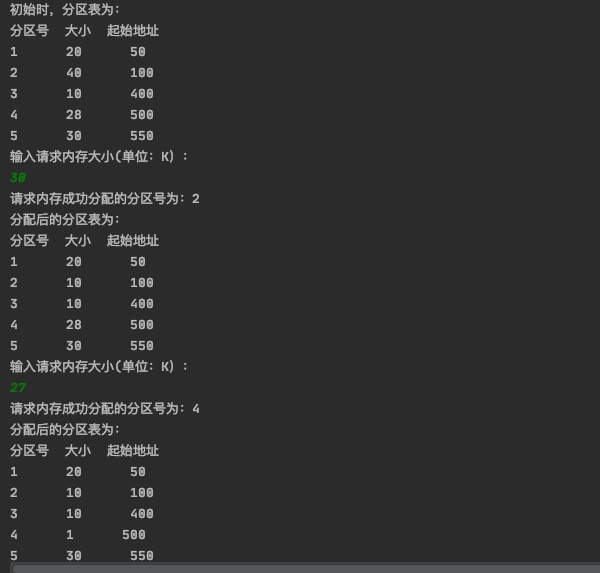
回收内存:
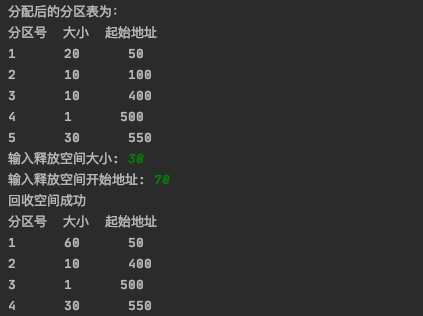
回收分区恰好与前后空闲分区相邻,所以1号分区,回收分区,和2号分区直接合并成一块分区,编号为1,其实地址为1号分区起始地址50,大小为20+30+10 = 60
第二次实验课把剩下的三个实验完成啦,也成功在老师面前验收完成,是全班第二快完成验收的,还是蛮有成就感的
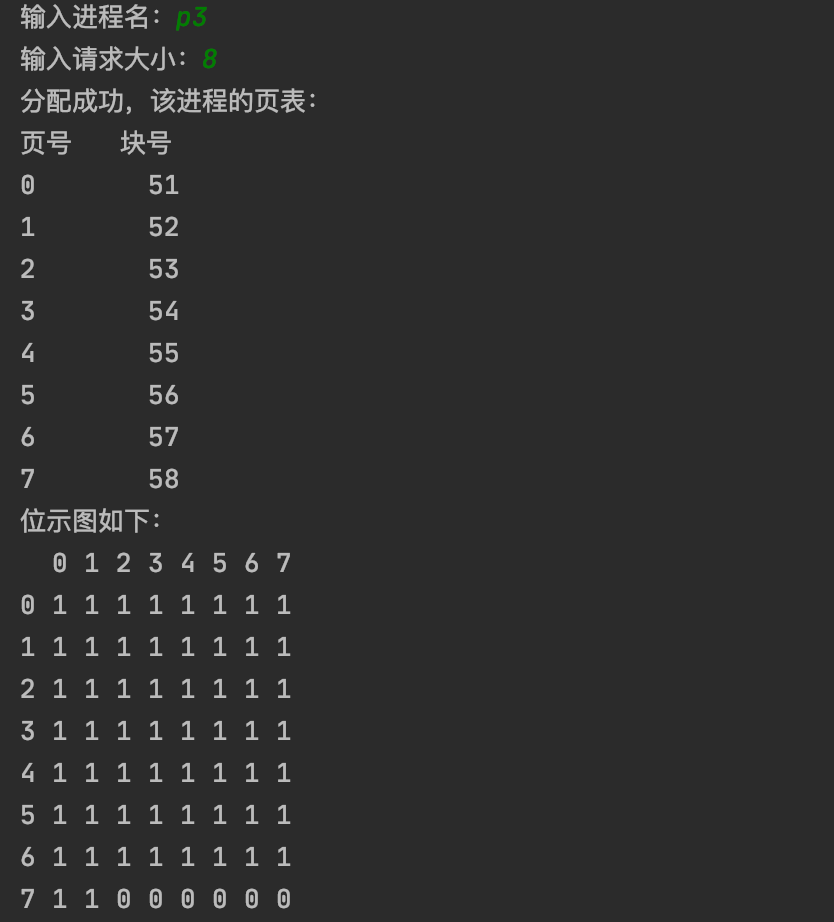
*在分页管理方式下采用位示图来表示主存分配情况,实现主存分配和回收*
*[提示]:*
(1) *假定系统的主存被分成大小相等的64个块,用0/1对应空闲/占用。*
(2) *当要装入一个作业时,根据作业对主存的需求量,先查空闲块数是否能满足作业要求,若能满足,则查位示图,修改位示图和空闲块数。位置与块号的对应关系为:*
*块号=**j*8+i**,其中**i**表示位,**j**表示字节。*
*根据分配的块号建立页表。页表包括两项:页号和块号。*
(3) *回收时,修改位示图和空闲块数。*
*要求能接受来自键盘的空间申请及释放请求,能显示**位示图和空闲块数的变化,能显示进程的页表。*
由于实验三选用了可变分区管理方式,验收的时候实验二有点问题,所以实验二重新选了分页管理方式
在验收的时候,老师专门要求提高鲁棒性,第一遍没有通过,,又修改了一部分才完成
运行截图如下:
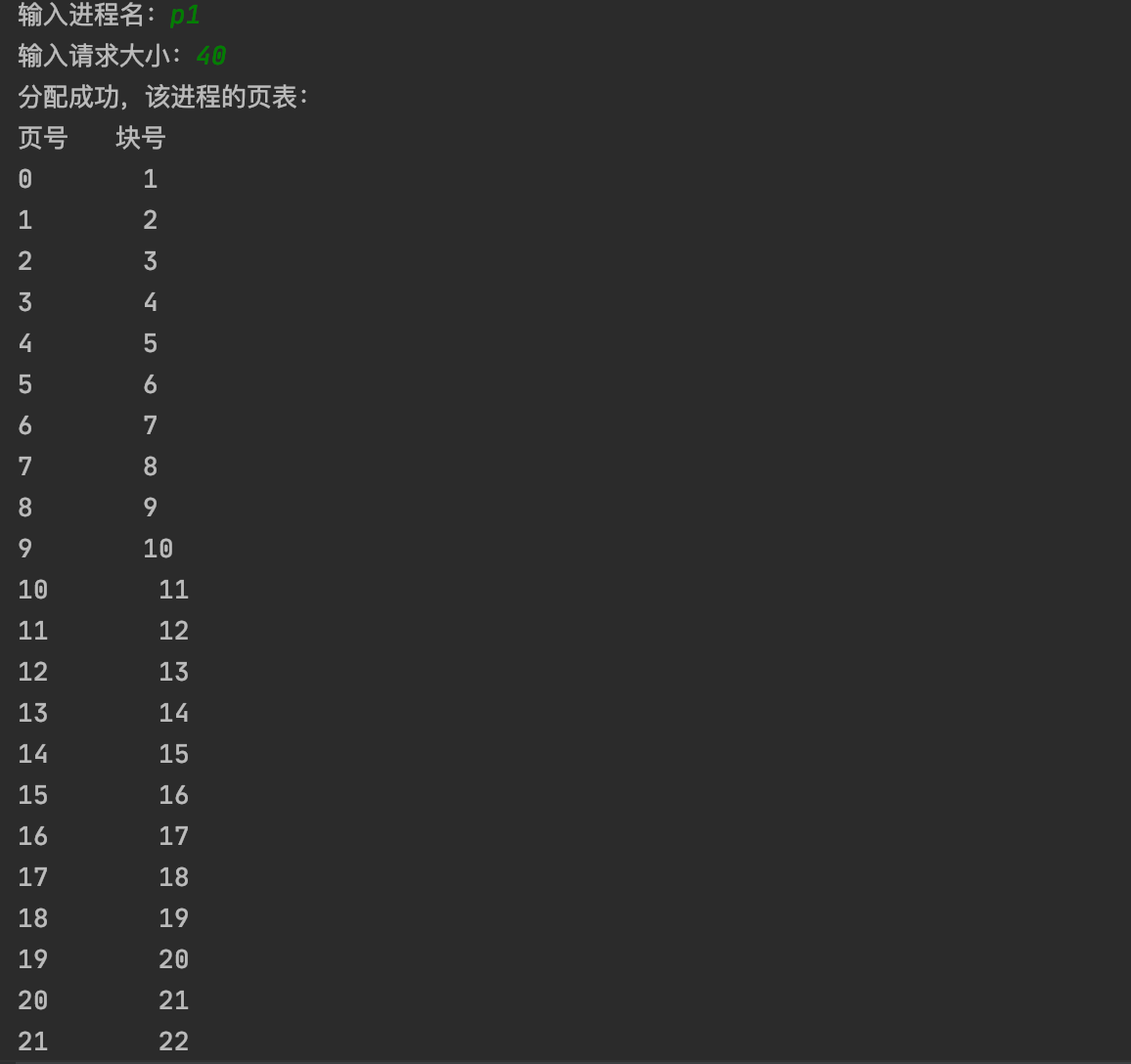
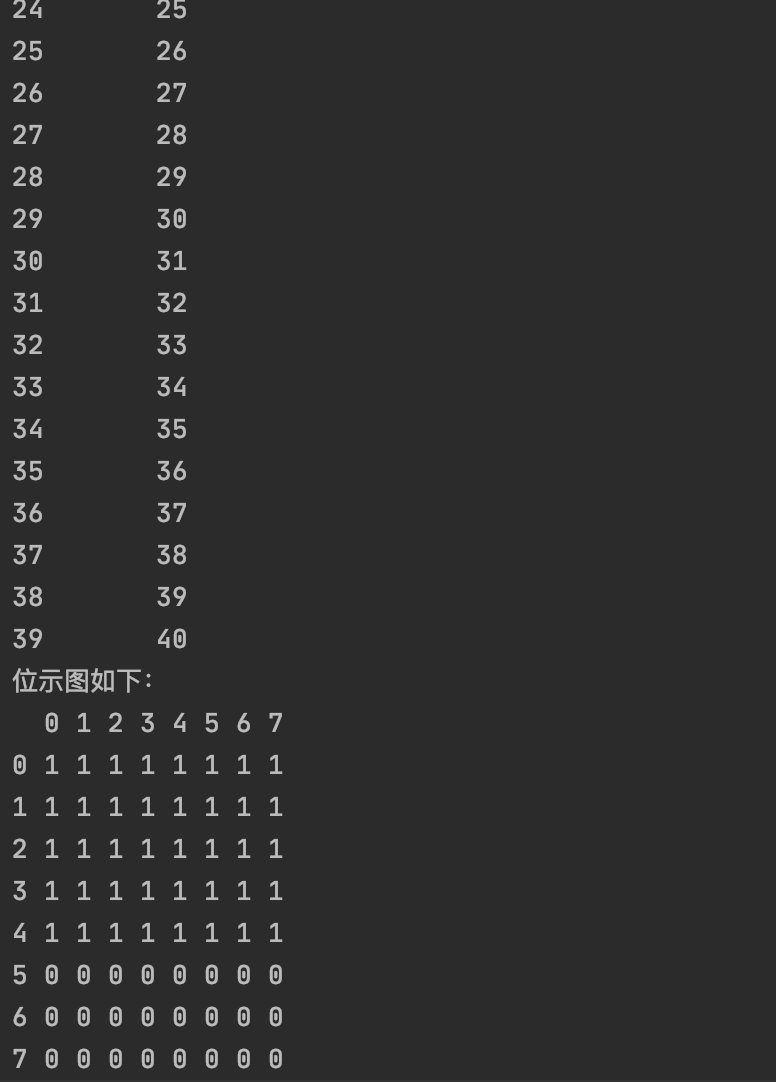
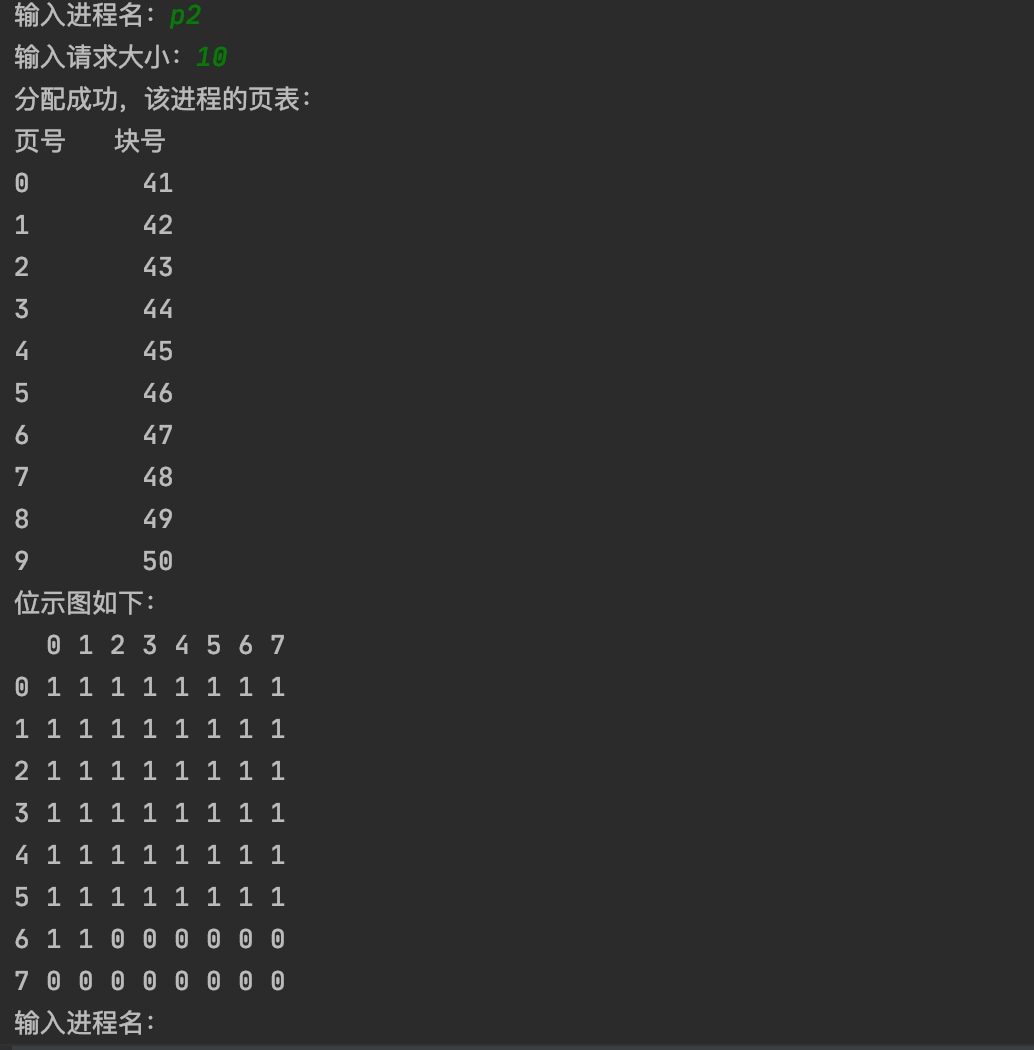
*一、实习内容*
*模拟磁盘空闲空间的表示方法,以及模拟实现磁盘空间的分配和回收。*
*二、实习目的*
*磁盘初始化时把磁盘存储空间分成许多块(扇区),这些空间可以被多个用户共享。用户作业在执行期间常常要在磁盘上建立文件或把已经建立在磁盘上的文件删去,这就涉及到磁盘存储空间的分配和回收。一个文件存放到磁盘上,可以组织成顺序文件(连续文件)、链接文件(串联文件)、索引文件等,因此,磁盘存储空间的分配有两种方式,一种是分配连续的存储空间,另一种是可以分配不连续的存储空间。怎样有效地管理磁盘存储空间是操作系统应解决的一个重要问题,通过本实习使学生掌握磁盘存储空间的分配和回收算法。*
*三、实习题目*
*本实习有三个题目,可以任选一个,**但不能与内存管理的题目类似**。*
*第一题:连续磁盘存储空间的分配和回收*
*[提示]:*
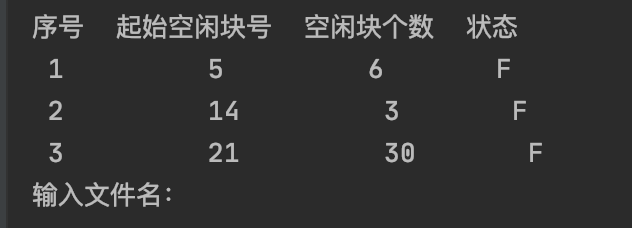
*(1)* *要在磁盘上建立顺序文件时,必须把按序排列的逻辑记录依次存放在磁盘的连续存储空间中。可假定磁盘初始化时,已把磁盘存储空间划分成若干等长的块(扇区),按柱面号和盘面号的顺序给每一块确定一个编号。随着文件的建立、删除、磁盘存储空间被分成许多区(每一区包含若干块),有的区存放着文件,而有的区是空闲的。当要建立顺序文件时必须找到一个合适的空闲区来存放文件记录,当一个文件被删除时,则该文件占用的区应成为空闲区。为此可用一张空闲区表来记录磁盘存储空间中尚未占用的部分,格式如下:*
| *序 号* | *起始空闲块号* | *空闲块个数* | *状 态* |
|---|---|---|---|
| *1* | *5* | *6* | *未 分 配* |
| *2* | *14* | *3* | *未 分 配* |
| *3* | *21* | *30* | *未 分 配* |
| *4* | |||
| *。。。* |
*(2)* *建立文件时,先查找空闲区表,从空闲区表中找出一个块数能满足要求的区,由起始空闲块号能依次推得可使用的其它块号。若不需要占用该区的所有块时,则剩余的块仍应为未分配的空闲块,这时要修改起始空闲块号和空闲块数。若占用了该区的所有块,则删去该空闲区。删除一个文件时,需要考虑空闲块的合并情况。*
*磁盘存储空间的分配和回收算法类似于主存储器的可变分区方式的分配和回收。同学们可参考实习二的第一题。*
*(3)* *当找到空闲块后,必须启动磁盘把信息存放到指定的块中,启动磁盘必须给出由三个参数组成的物理地址:盘面号、柱面号和物理记录号(即扇区号)。故必须把找到的空闲块号换算成磁盘的物理地址。*
*为了减少移臂次数,磁盘上的信息按柱面上各磁道顺序存放。现假定一个盘组共有200个柱面,(编号0-199)每个柱面有20个磁道(编号0-19,同一柱面上的各磁道分布在各盘面上,故磁道号即盘面号。),每个磁道被分成等长的6个物理记录(编号0-5,每个盘面被分成若干个扇区,故每个磁道上的物理记录号即为对应的扇区号)。那么,空闲块号与磁盘物理地址的对应关系如下:*
*则 物理记录号* *=* *空闲块号 % 6*
*磁道号=(空闲块号 / 6 )% 20*
*柱面号=(空闲块号 / 6)/20*
*(4)* *删除一个文件时,从文件目录表中可得到该文件在磁盘上的起始地址和逻辑记录个数,假定每个逻辑记录占磁盘上的一块,则可推算出归还后的起始空闲块号和块数,登记到空闲区表中。换算关系如下:*
*起始空闲块号=(柱面号**´**20+磁道号)**´**6+物理记录号*
*空闲块数=逻辑记录数*
*(5)* *请设计磁盘存储空间的分配和回收程序,要求把分配到的空闲块转换成磁盘物理地址,把归还的磁盘空间转换成空闲块号。*
*要求能接受来自键盘的空间申请及释放请求,能**显示或打印分配及回收后的空闲区表以及分配到的磁盘空间的起始物理地址:包括柱面号、磁道号、物理记录号(扇区号)。*
这个实验看起来复杂,实际做起来和第二个实验的可变分区管理内存的思路基本一样,只不过需要增加一个磁盘位置。
运行截图:
起始时,我分配了在块表中分配了3个表项,状态F表示未被使用
提示用户输入文件名,需要的空闲块:
程序返回系统分配的起始块号,磁盘上的起始物理记录号,磁道号,柱面号
并将文件的存储信息展示出来:

再存入一个:

释放空间时,只需要输入文件名称,即可从磁盘空间移除:

*1.1**实验目的*
即fork()被调用了一次,但返回了两次。此时OS在内存中建立一编制一段程序,程序中可包含变量,代码至少执行三个系统调用fork( )创建子(孙)进程。要求:
每个进程执行时都在屏幕上显示进程号及其父进程号;
输出进程中的变量取值,以观察子孙进程中的同名变量的关系。
给出实验的结果及你对fork()这一系统调用的分析理解。
[提示]:
(1)可用fork()系统调用来创建一个新进程。
系统调用格式:pid=fork()
在该系统调用之前和之后加上一些输出语句,观察子进程可以执行的语句是什么范围的???
fork()返回值意义如下:
wait();之后的语句的执行时机?
=0:若返回值为0,表示当前进程是子进程。
>0:若返回值大于0,表示当前进程是父进程,返回值为子进程的pid值。
-1:若返回值小于0,表示进程创建失败。
如果fork()调用成功,它向父进程返回子进程的pid,并向子进程返回0,个新进程,所建的新进程是调用fork()父进程的副本,称为子进程。子进程继承了父进程的许多特性,并具有与父进程完全相同的用户级上下文。父进程与子进程并发执行。
(2)编译和执行的方法:
gcc 源文件名 -o 执行文件名
最后,在shell提示符下输入: ./执行文件名
*1.2**实验意义*
本实习利用fork()系统进行调用,了解进程的创建过程,进一步理解进程的概念,明确进程和程序的区别。
*1实验设计*
*2.1* *概述*
程序使用C语言,开发工具信息:
版本: 1.56.2
提交: 054a9295330880ed74ceaedda236253b4f39a335
日期: 2021-05-12T17:44:30.902Z
Electron: 12.0.4
Chrome: 89.0.4389.114
Node.js: 14.16.0
V8: 8.9.255.24-electron.0
OS: Darwin x64 20.3.0
程序中,我调用了3次fork(),创建同名变量cnt,用于观察父子进程对该同名变量的修改情况。
*2.2* *实验原理*
根据课堂ppt及课后查阅的资料,我了解了fork()系统调用的功能:
系统调用fork用于创建一个新进程。
fork系统调用的语法格式如下:
int fork( )
fork系统调用没有参数,如果执行成功,则创建一个子进程,子进程继承父进程的许多特性,并具有与父进程完全相同的用户级上下文。
fork()的算法描述如下:
算法 fork,无输入参数,父进程返回子进程PID,子进程返回0
{ 检查可用的内核资源;
取一个空闲的进程表项和惟一的PID号;
检查用户没有过多运行进程;
将子进程的状态设置为“创建”状态;
将父进程进程表项的数据拷贝到子进程进程表项中;
当前目录和根目录的索引节点引用计数加1;
文件表中打开文件的引用计数加1;
在内存中作父进程上下文的拷贝;
在子进程的系统级上下文中压入虚设系统级上下文层;
if (正在执行的进程是父进程)
{ 将子进程的状态设置为“就绪”状态;
return(子进程的PID);
}
else {
初始化U区的计时域;
return(0);
}}
*2.3* *实验方案*
程序初始时,我设置了共享变量cnt = 0
接着打印main进程的父进程的pid
然后调用fork()创建进程p1,fork()的返回值遵循以下规则:
在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的几乎完全相同,将要执行的下一条语句都是if(fpid<0)……
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
因此,通过判断fork()返回值是否大于0,等于0或着小于0,可以判断该进程时父进程或是子进程。
该段判断代码如下:
id_t p1 = fork(); //创建子进程p1,会执行和父进程相同的代码
if (p1 == 0)
{
printf("childpid = %d, parentpid = %d\n", getpid(), getppid());
cnt++;
}
else if (p1 > 0)
{
printf("childpid = %d, parentpid = %d\n", getpid(), getppid());
}
else
{
printf("进程创建失败\n");
}
接着使用同样的逻辑,创建了2个进程p2和p3,在子进程中,使cnt+1,从而标识该进程对cnt的修改。
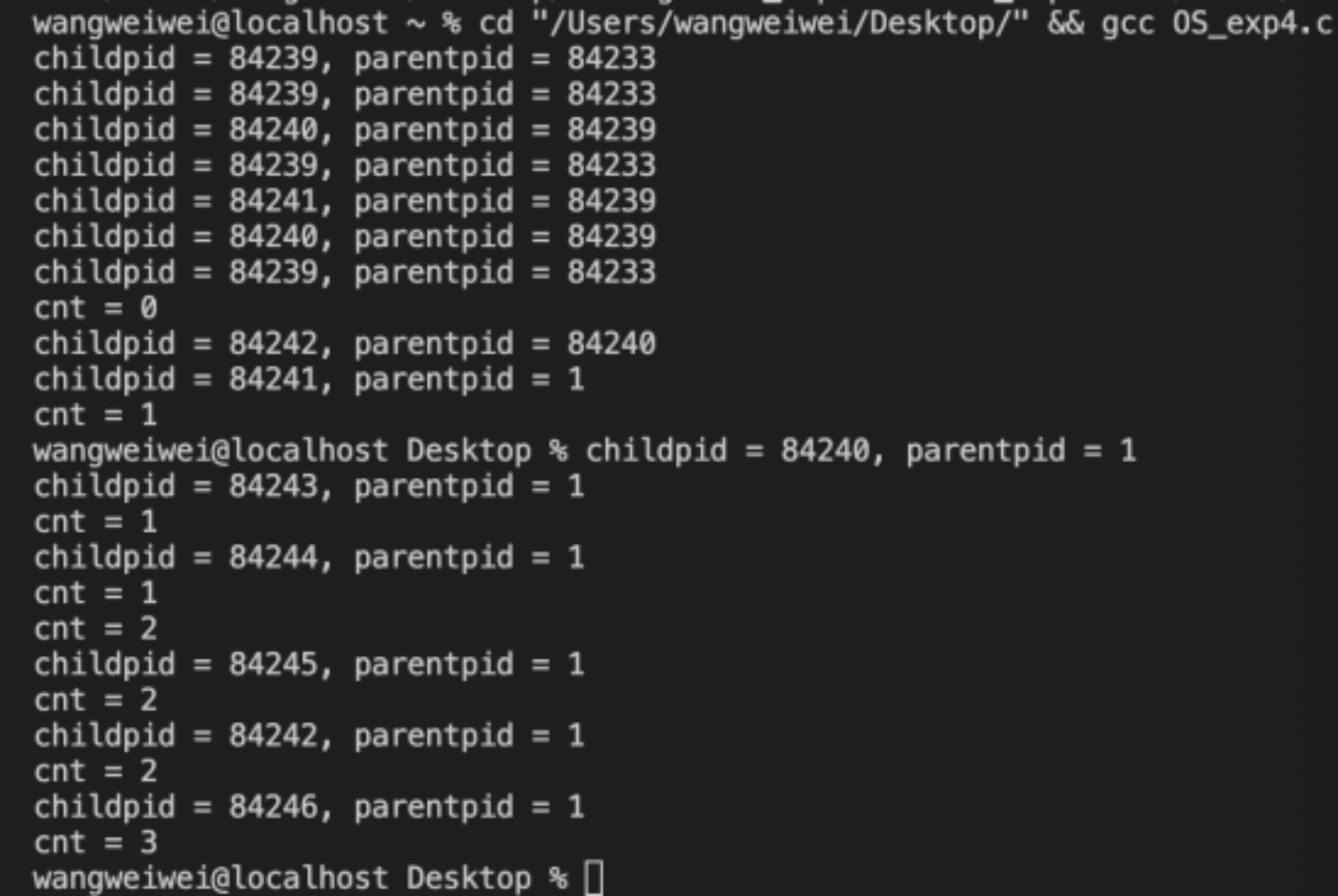
程序运行结果如图(a):
(a)
观察到,在程序运行到后面时,parentid=1,是个很有趣的现象。查阅资料后分析得知,因为父进程先于子进程结束,则子进程打印父进程pid为1。这表明:在本次执行过程中84243,84244,84245,84242,84246进程的父进程均先于他们的子进程结束,因此会出现这种情况。
生产者—消费者问题。
假定有一个生产者和一个消费者,生产者每次生产一件产品,并把生产的产品存入共享缓冲器以供消费者取走使用。消费者每次从缓冲器内取出一件产品去消费。禁止生产者将产品放入已满的缓冲器内,禁止消费者从空缓冲器内取产品。假定缓冲器内可同时存放10件产品,用P、V操作来实现生产者和消费者之间的同步,生产者和消费者两个进程的程序如下:
B: array [0..9] of products;
s1, s2; semaphore;
s1: =10, s2: =0;
IN, out: integer;
IN: =0; out: =0;
cobegin
procedure producer;
c: products;
begin
L1:
Produce (c);
P (s1);
B[IN]: =C;
IN: =(IN+1)mod 10;
V (s2);
goto L1
end;
procedure consumer;
x: products;
begin
L2: p (s2);
x: =B[out];
out: =(out+1) mod10;
v (s1);
consume (x);
goto L2
end;
coend.
其中的semaphore和products是预先定义的两个类型,在模拟实现中semaphore用integer代替,products可用integer或char等代替。
*1.2**实验意义*
本实习通过高级语言模拟生产者—消费者问题,加深对PV原语的理解。
*1实验设计*
*2.1* *概述*
程序使用JAVA语言进行模拟,开发工具使用IntelliJ IDEA
版本信息如下:
IntelliJ IDEA 2020.2.4 (Ultimate Edition)
Build #IU-202.8194.7, built on November 24, 2020
Licensed to Wang weiwei
Subscription is active until September 12, 2021
For educational use only.
Runtime version: 11.0.9+11-b944.49 x86_64
VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o.
macOS 10.16
GC: ParNew, ConcurrentMarkSweep
Memory: 990M
Cores: 4
Non-Bundled Plugins: com.intellij.zh, com.wakatime.intellij.plugin, org.jetbrains.kotlin
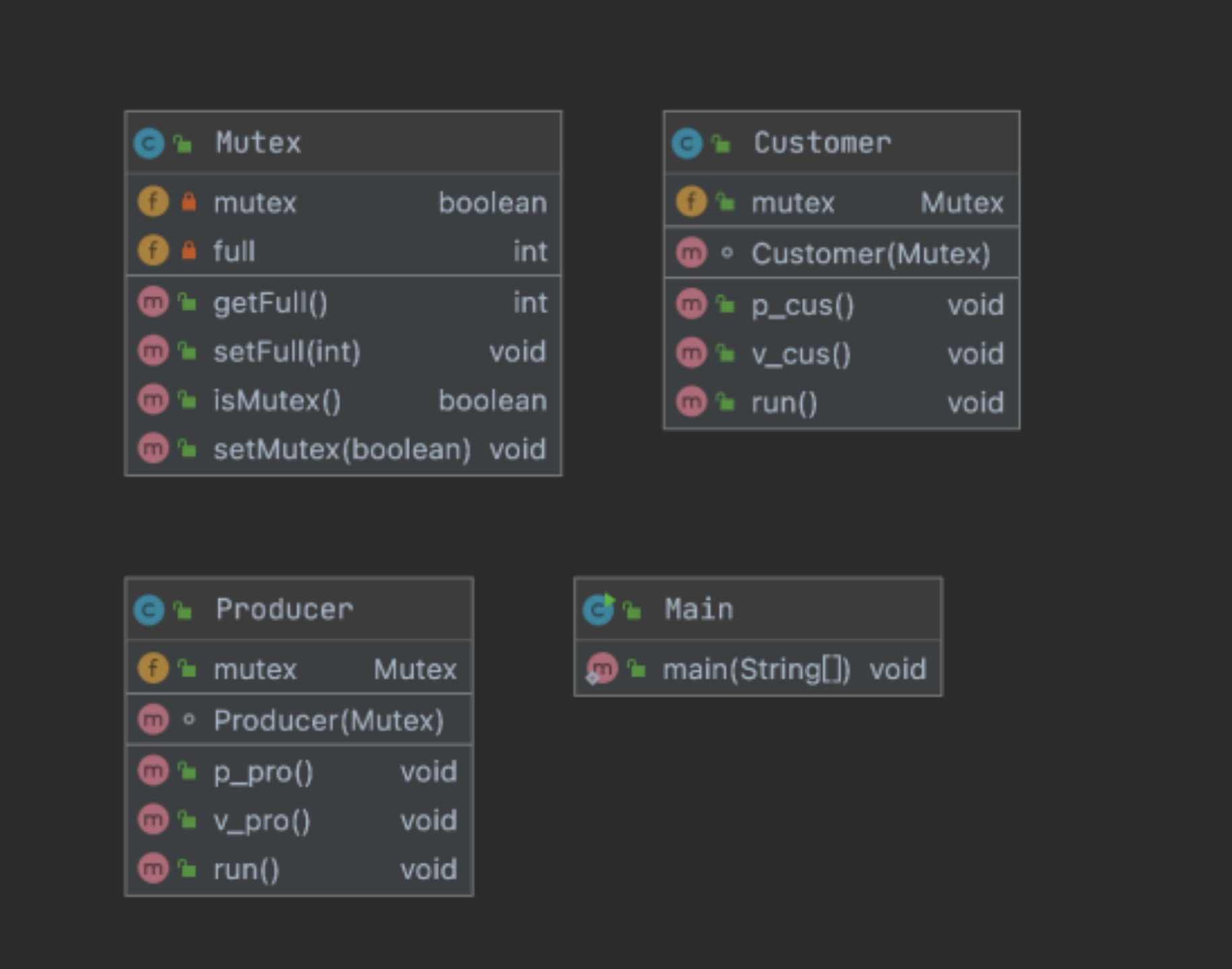
JAVA类图设计如图a:
(a)
我设置了4个类,分别是Main:于控制程序运行逻辑;Mutex类:用于模拟互斥变量;Customer类用于模拟分配表项,File类用于模拟文件。
在Main中,我执行了300次循环,每次循环创建随机数,根据随机数来决定是创建消费者进程还是生产者进程。
执行300次的主要目的就是为了达到20次,使缓冲区满,从而达到检测缓冲区满时,程序运行情况。
*2.2* *实验原理*
利用高级程序设计语言JAVA,进行算法设计,模拟连模拟实现同步机构,以避免发生进程执行时可能出现的与时间有关的错误。
*2.3* *实验方案*
*2.4.1 模块设计*
2.4.1.1 Mutex类
Mutex类为实体类,包含两个属性,以及get/set方法
属性字段如下:
private boolean mutex; //标识临界变量是否可用
private int full; //满缓冲区数目
2.4.1.2 Producer类
Producer类主要用于模拟生产者进程,P操作为,若缓冲区未满,则将生产的产品放入缓冲区,若已满,则提示用户仓库已满,无法生产。
该类继承了Thread类,重写了run()方法,在run()方法中,执行p_pro()和v_pro()操作。
2.4.1.3 Customer类
Customer类主要用于模拟消费者进程,P操作为,若缓冲区有产品,则消费者将从缓冲区取出一件产品,并提示用户当前缓冲区产品剩余数。若缓冲区无产品,则提示当前缓冲区空,若生产者正在使用缓冲区,则提示用户当前缓冲区正在被占有,无法消费。
2.4.2 程序运行过程
程序一次执行循环300次,由于数目太大,这里我挑选几个有代表性的情况展示截图:
最开始执行时,缓冲区常常出现空的情况如图(b):

(b)
循环执行到中间部分时,此时大部分是消费者和生产者发生冲突,如图(c):
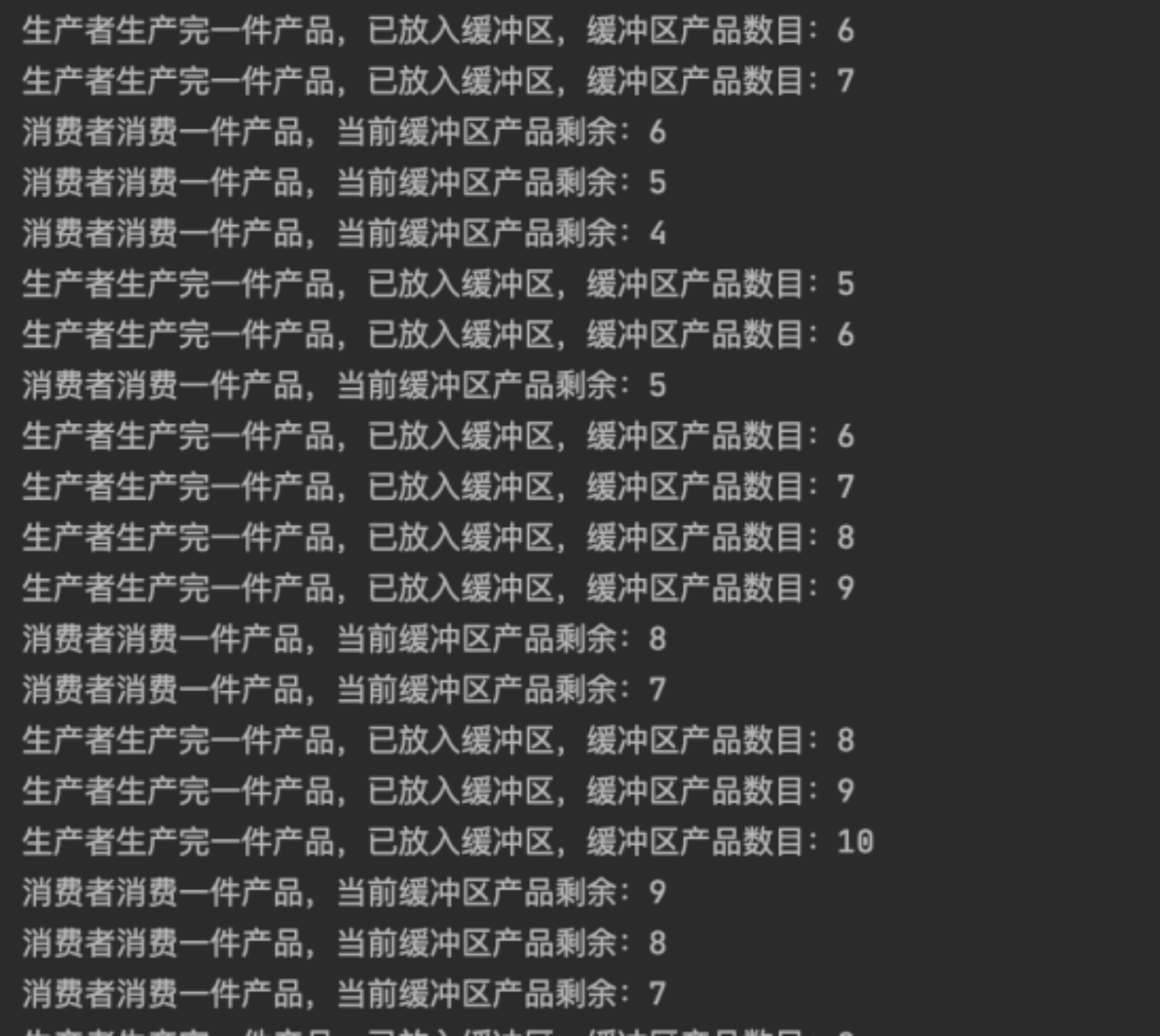
(c)
*结论*
实验使用Java高级语言成功模拟实现同步机构,以避免发生进程执行时可能出现的与时间有关的错误。在模拟过程中加深了对PV操作的理解。