Conversation
f5fbe61 to
83f2297
Compare
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
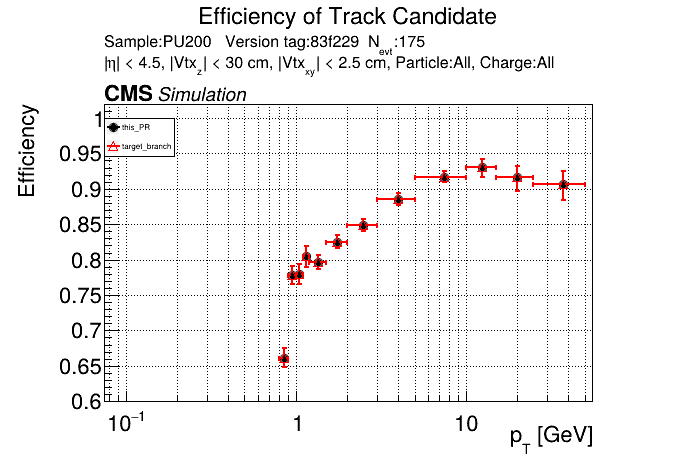
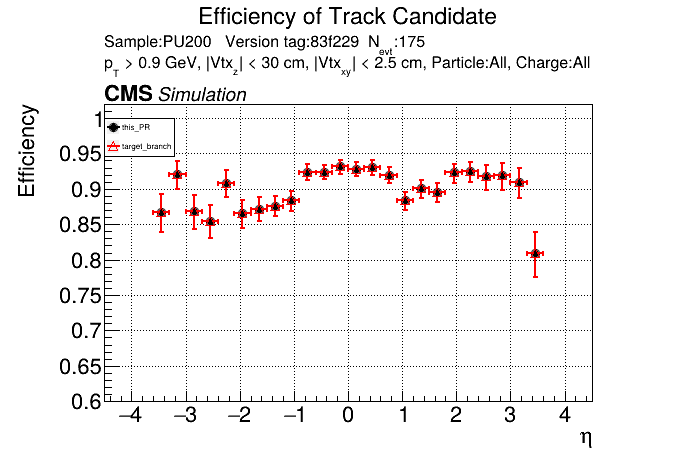
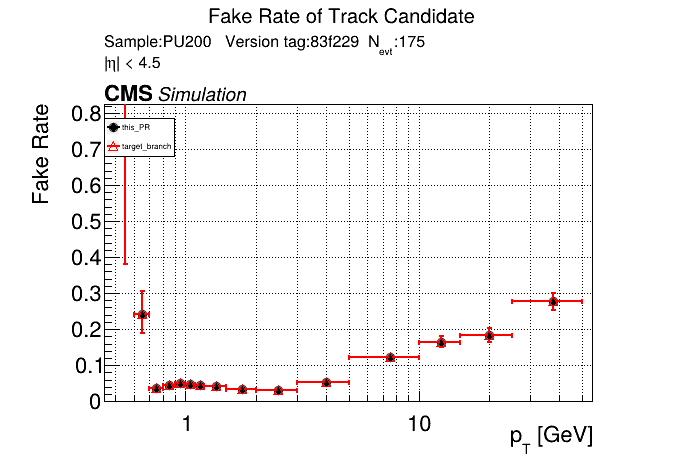
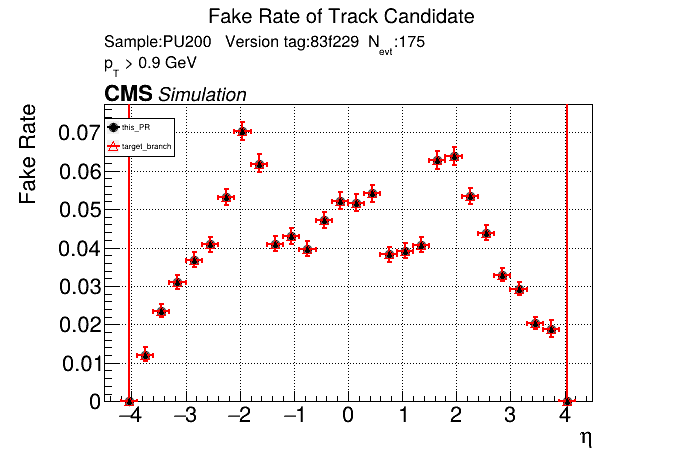
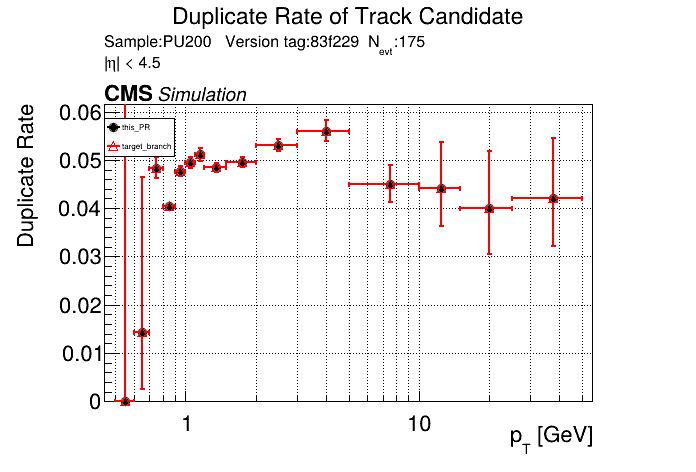
|
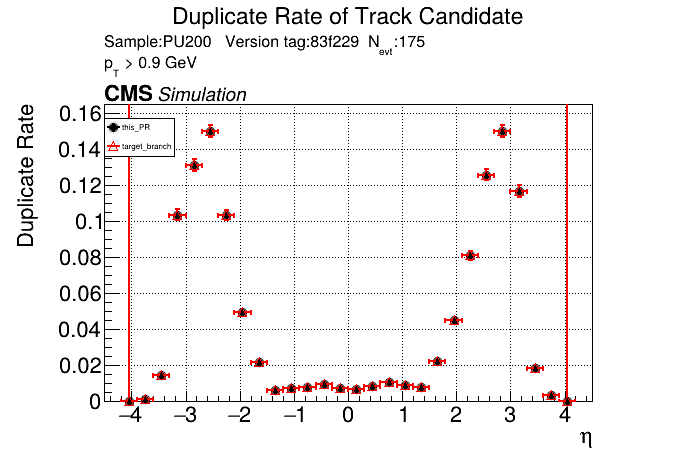
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
run-ci: all |
|
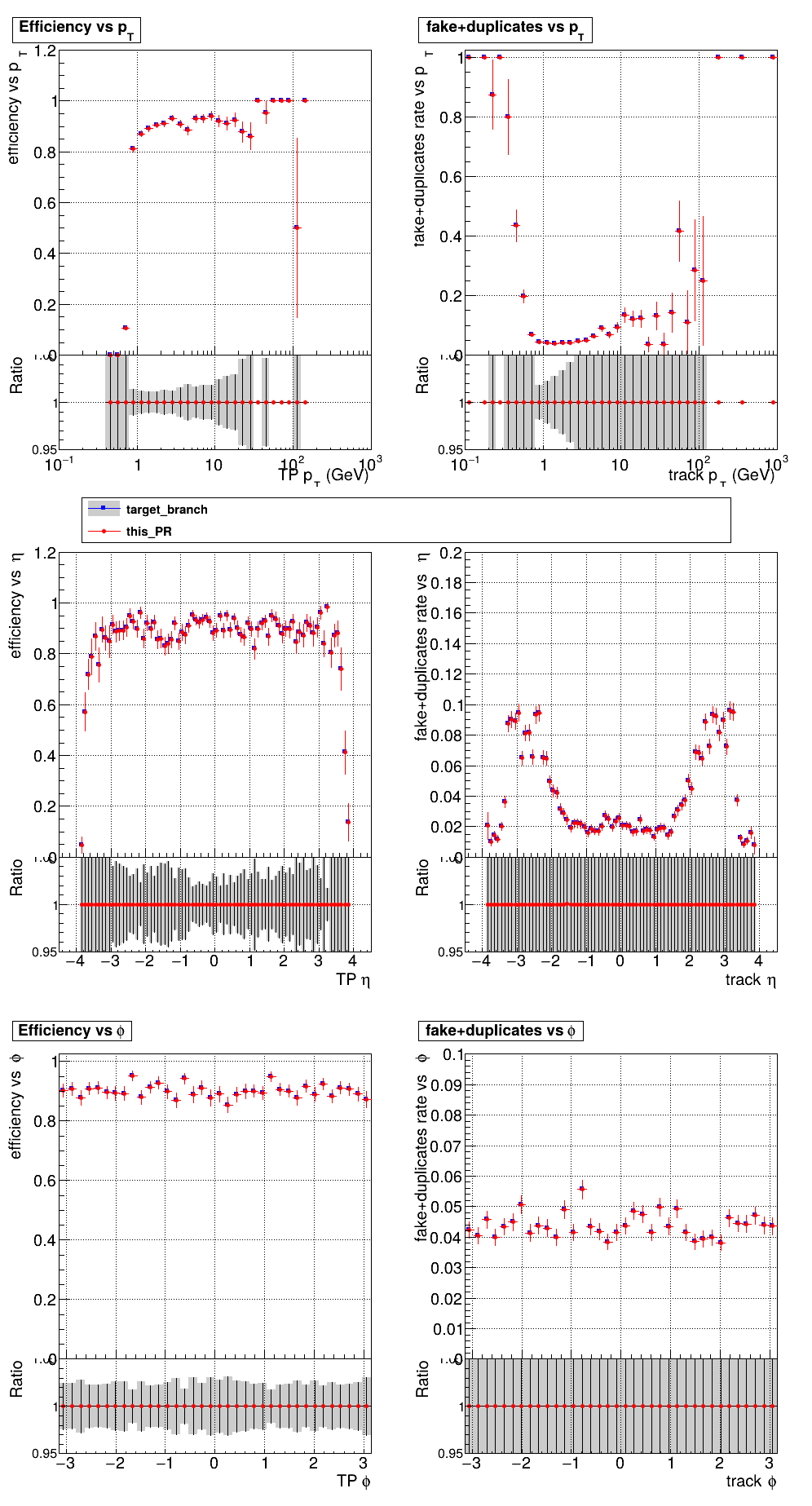
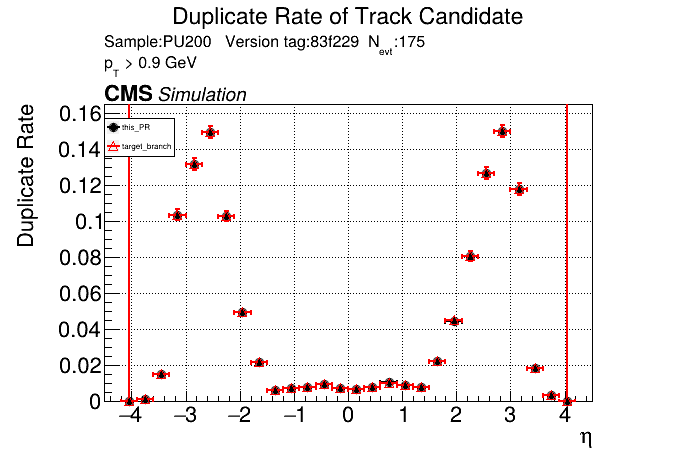
The PR was built and ran successfully in standalone mode running on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
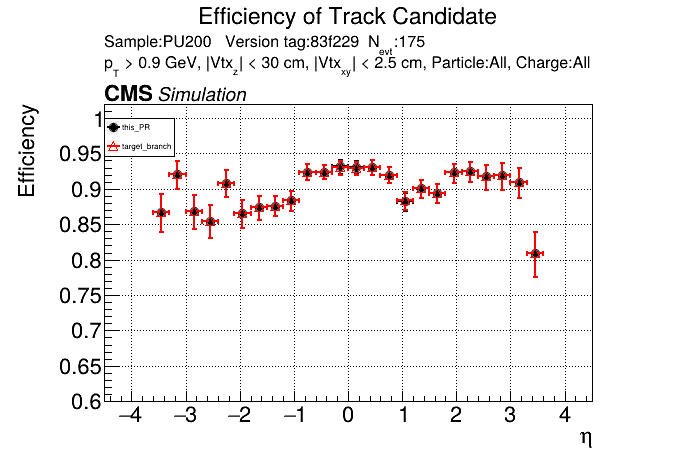
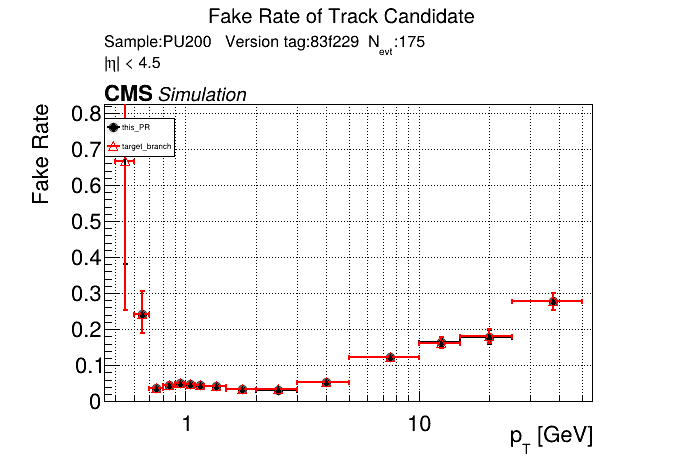
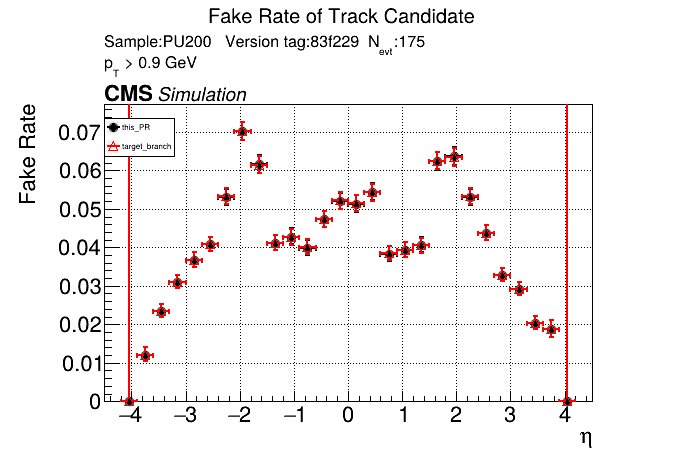
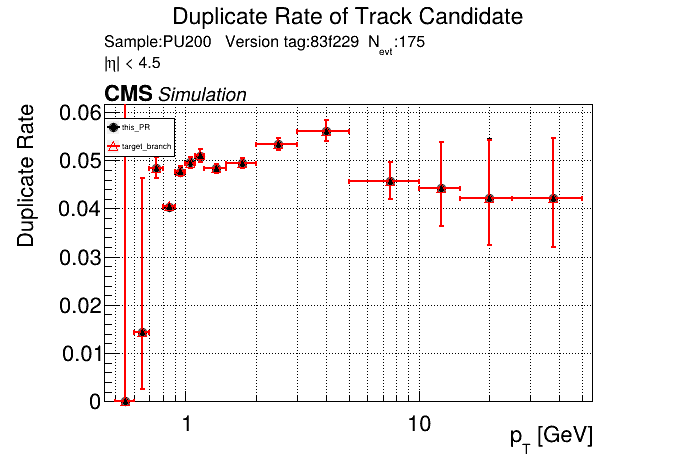
|
@slava77 I think this PR is good to go. Represents most of the boiler-plate changes of the CPU speedups PR. |
|
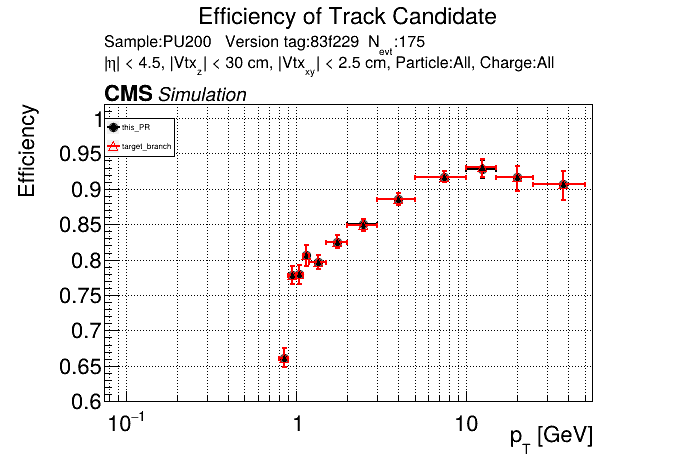
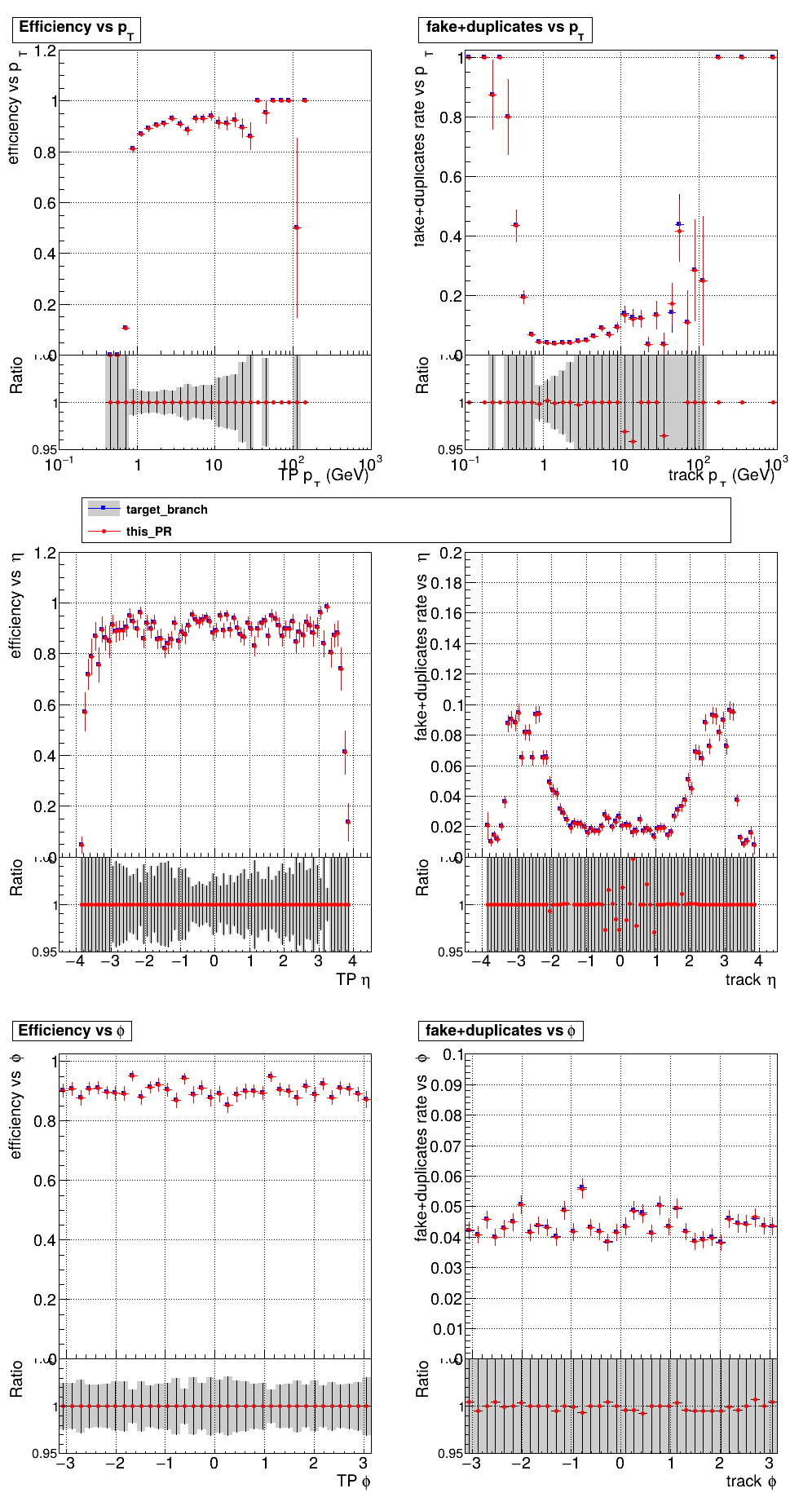
The PR was built and ran successfully with CMSSW running on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |

the GPU variant should have one more significant digit in the component columns (the total can be still with |
 slava77
left a comment
slava77
left a comment
There was a problem hiding this comment.
nice updates.
I think the comment cleanup in the MiniDoublet code is a bit too aggressive. While some removals may be clean for some tautological docs, quite a bit is going to lose clarity. Please recover
9aad224 to
727bac8
Compare
|
run-ci: all |
727bac8 to
2375562
Compare
|
run-ci: all |
|
run-ci: all |
|
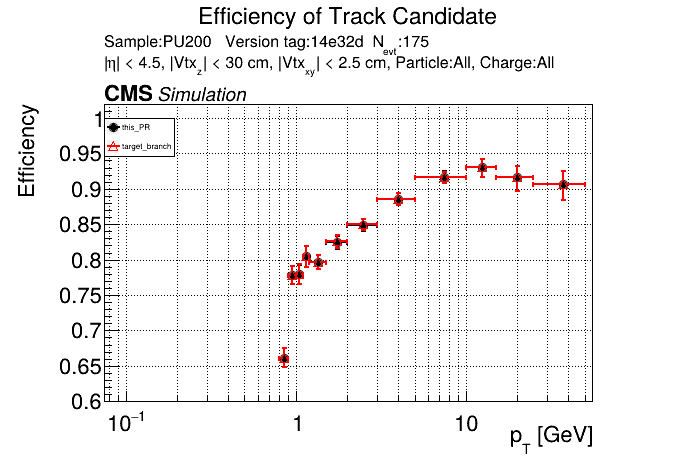
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
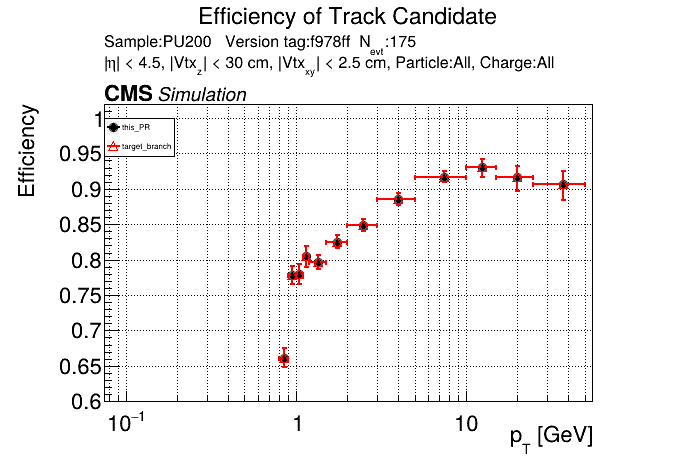
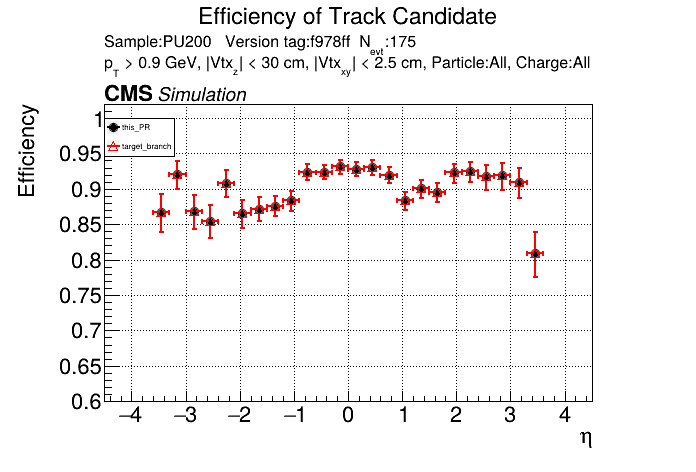
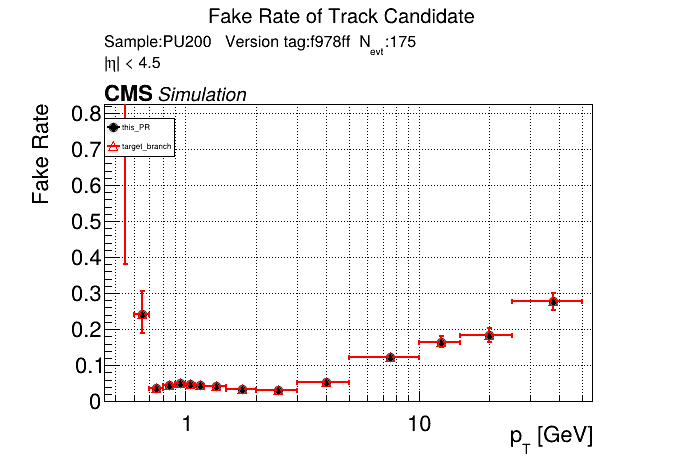
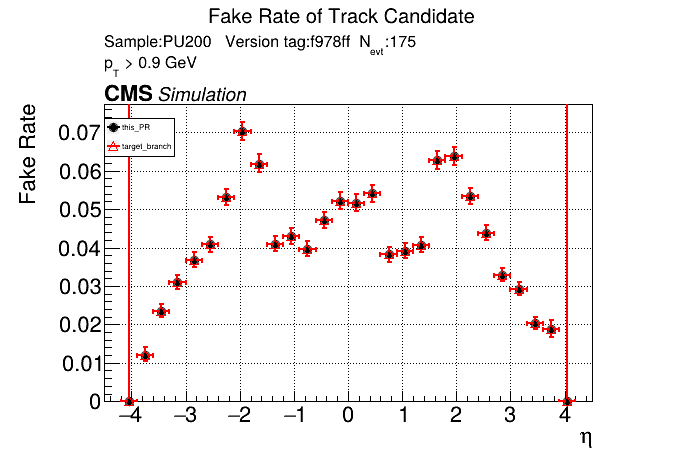
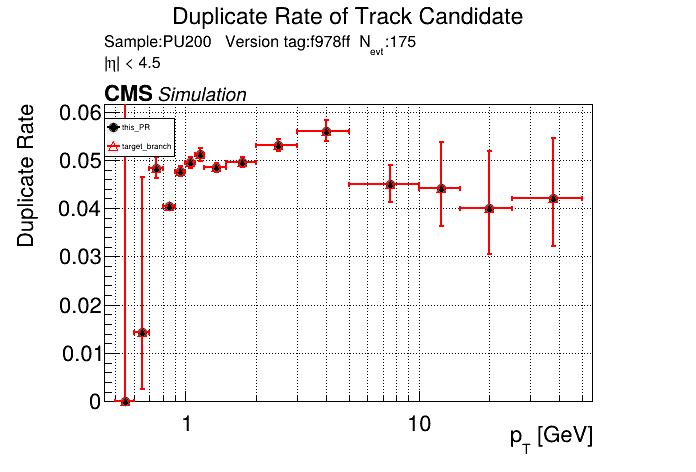
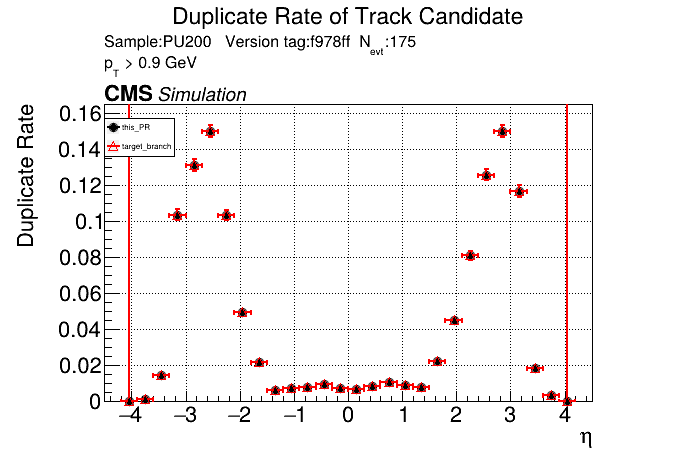
|
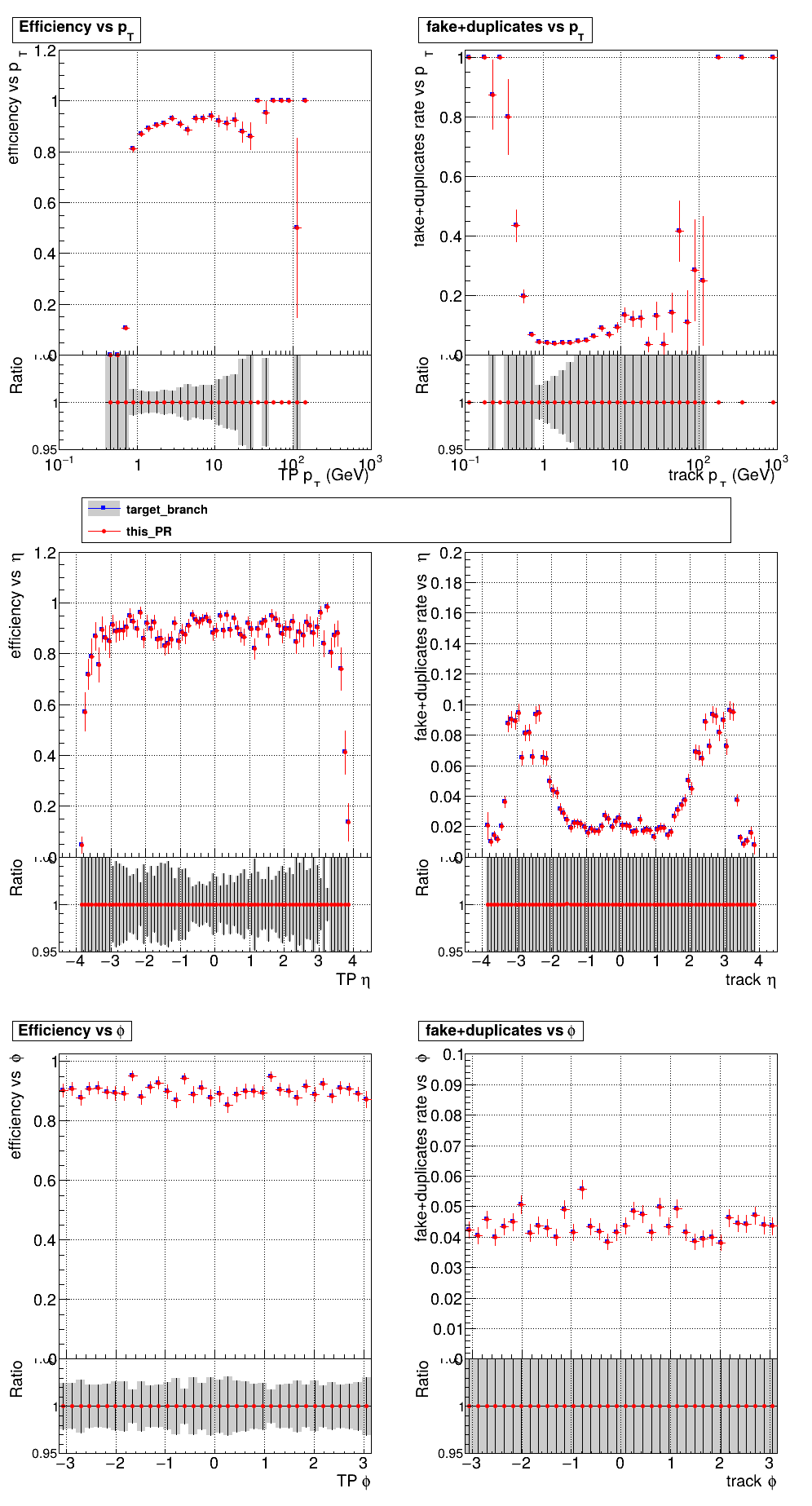
The PR was built and ran successfully with CMSSW running on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
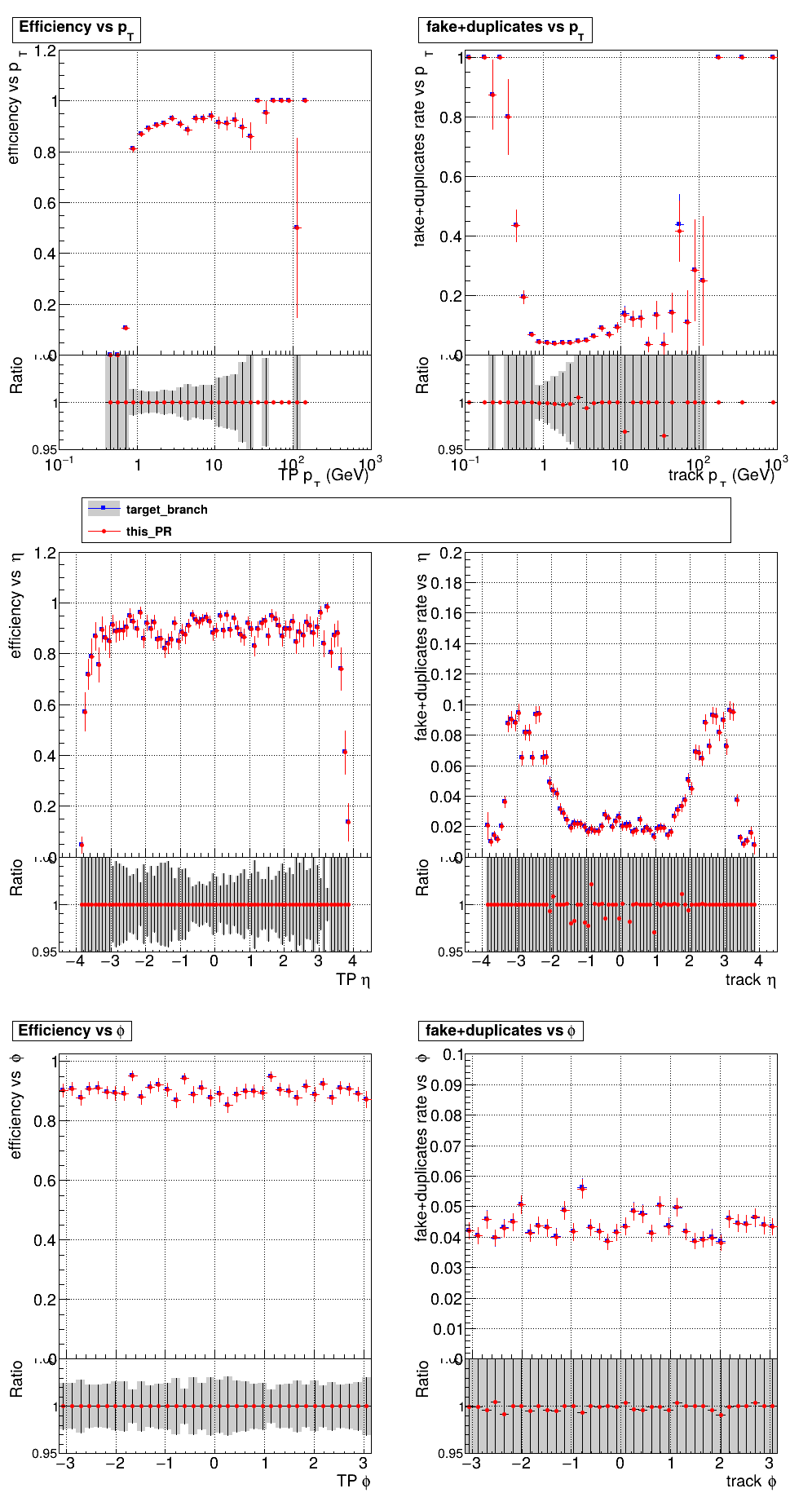
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
The PR was built and ran successfully in standalone mode running on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
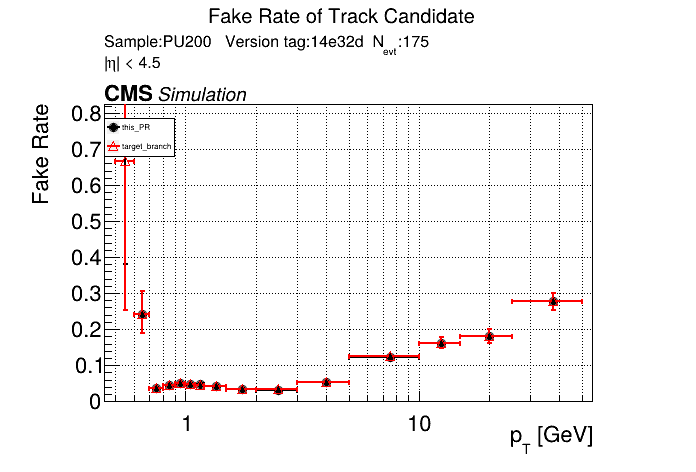
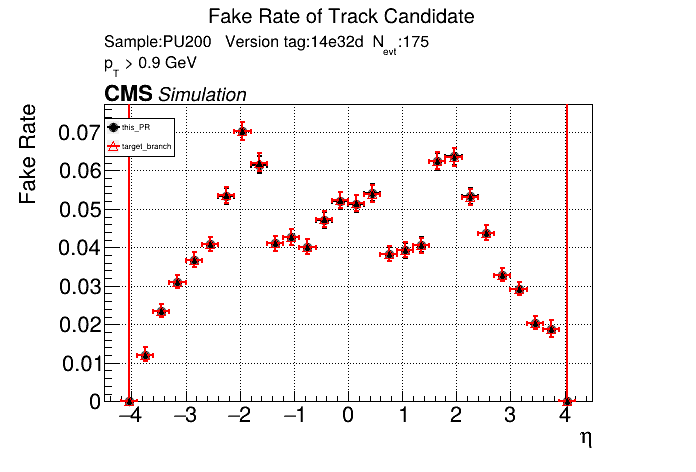
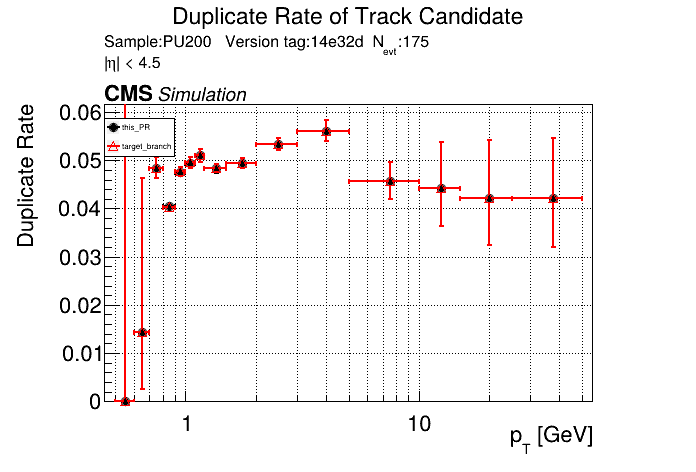
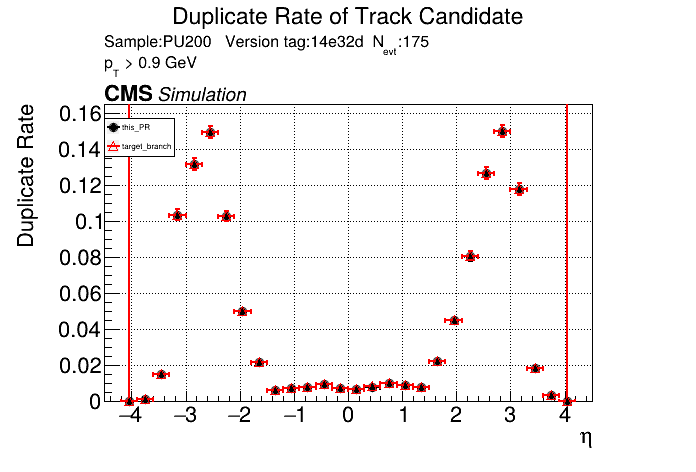
|
run-ci: all |
a2305fb to
df0990a
Compare
6ba26d8 to
912b6d9
Compare
03772d0 to
df8220c
Compare
|
@slava77 Can you check the changes in the segments file, I think I addressed your concerns |
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
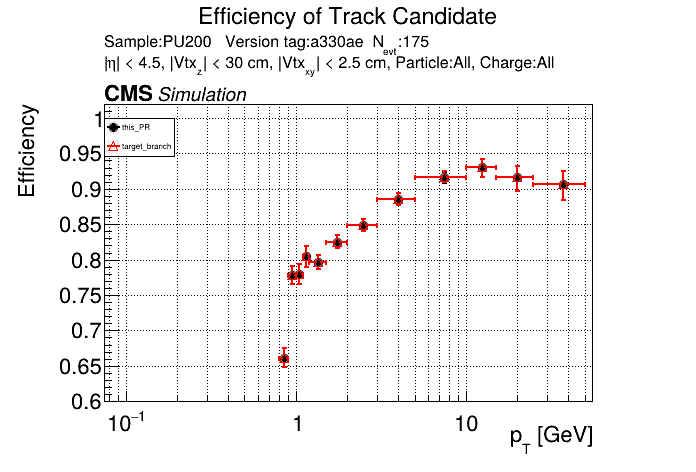
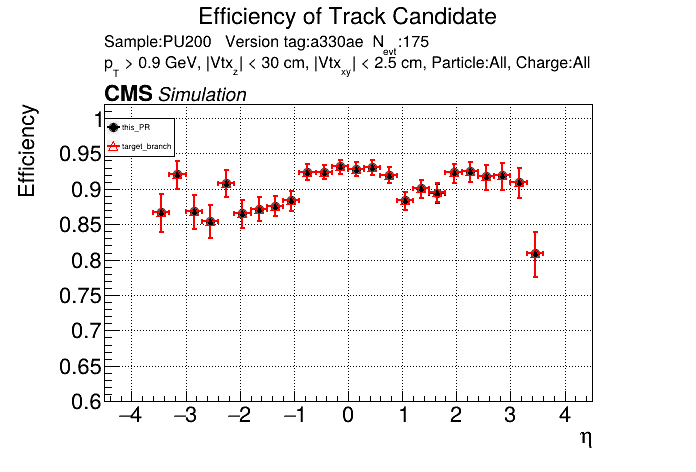
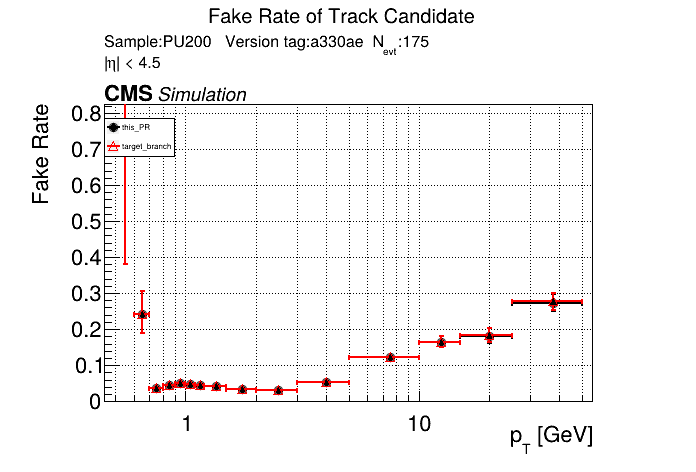
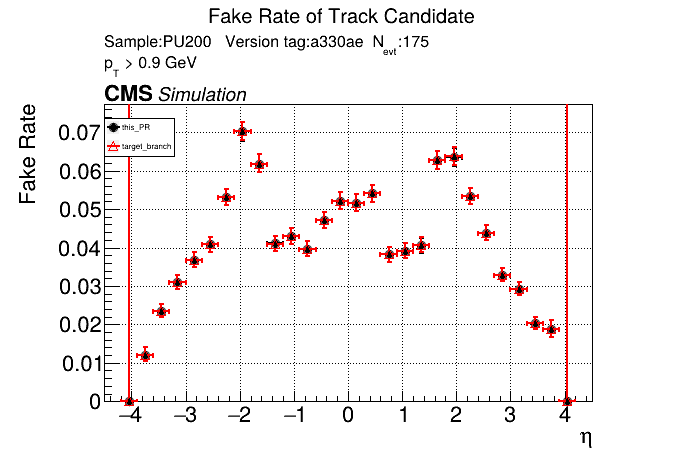
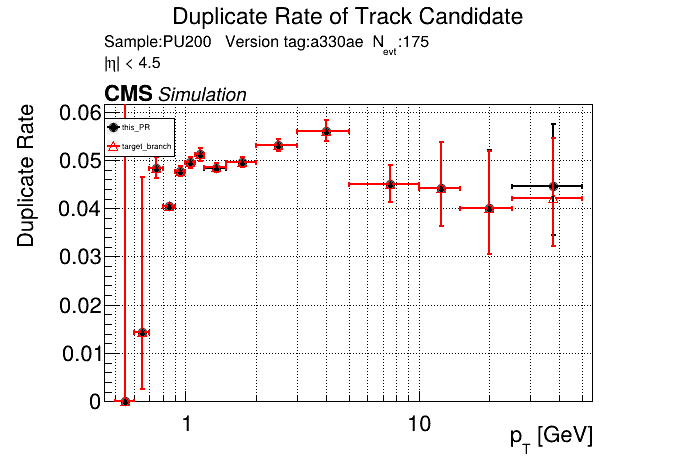
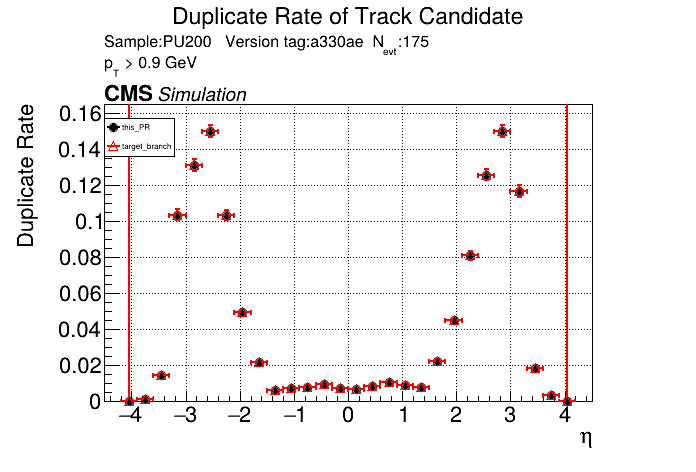
|
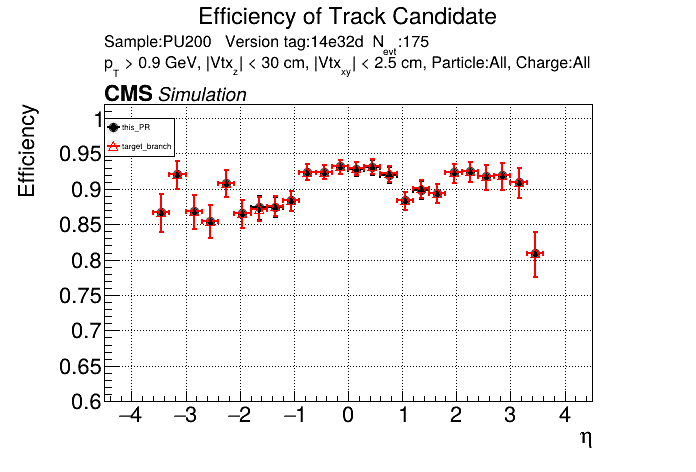
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
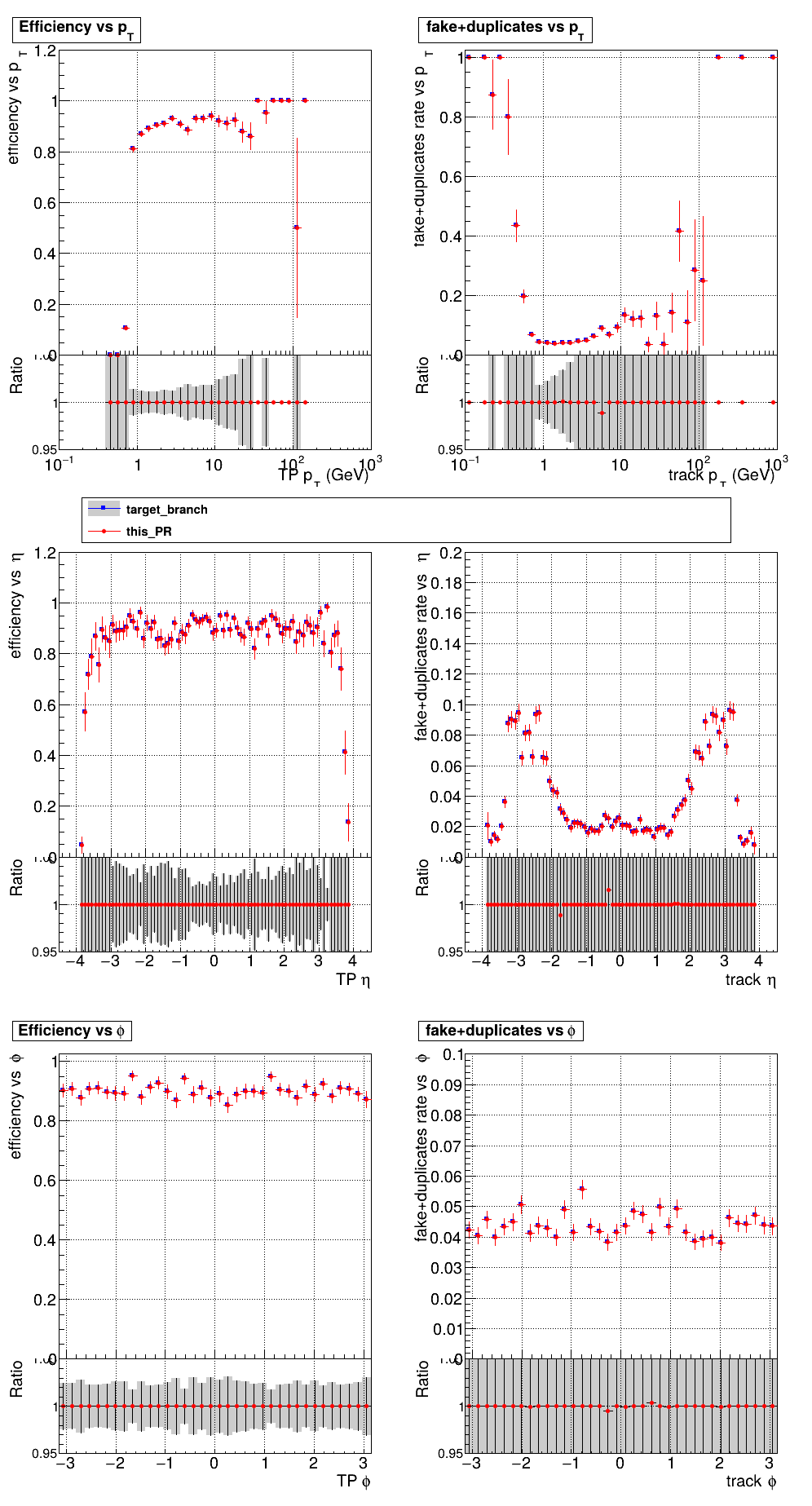
slava77
left a comment
There was a problem hiding this comment.
I suggest to set up a reviewing agent that ensures that similar changes remain consistently implemented in different places, including consistent naming
| @@ -799,21 +852,81 @@ namespace ALPAKA_ACCELERATOR_NAMESPACE::lst { | |||
|
|
|||
| template <alpaka::concepts::Acc TAcc> | |||
| ALPAKA_FN_ACC ALPAKA_FN_INLINE bool passDeltaPhiCutsSelector(TAcc const& acc, | |||
There was a problem hiding this comment.
I still don't understand the changes in this method.
Please don't just generate more code and clarify in plain English.
This method is used in CountMiniDoubletConnections and is logically meant to have either loose or full cuts.
The fact that dz cuts are added are probably OK, but on one hand it's a feature creep on another the method name is bad now.
Connected to the memory toggle PR, it's probably better to template this method to have a true/false loose/full cuts.
7a81541 to
3c415b4
Compare
|
@slava77 - Proof: Pre-checks in segments.h decreases timing for LS from 83.1 to 75.6 single stream. This PR Timing This PR Timing if I remove the two pre-checks in passDeltaPhiCutsBarrel and passDeltaPhiCutsEndcap |


3c415b4 to
117c197
Compare
|
I forgot a dphichange precheck in the MD endcap path, added it and the timing decreases from 62.6->47.7 |

|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
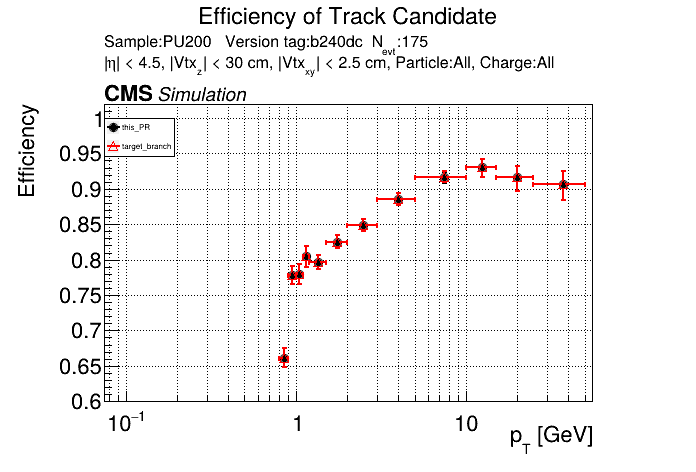
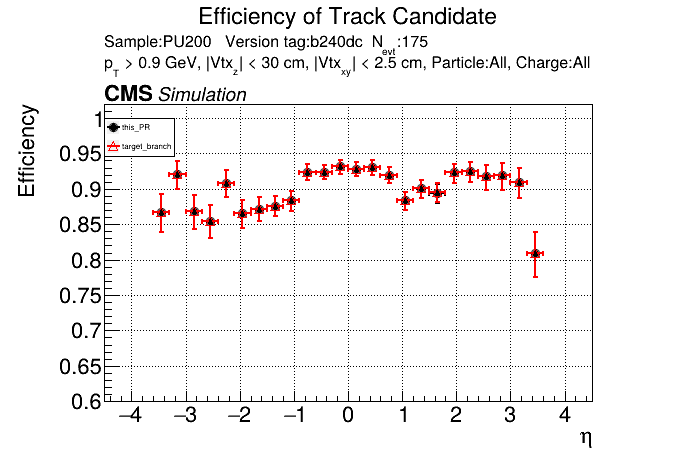
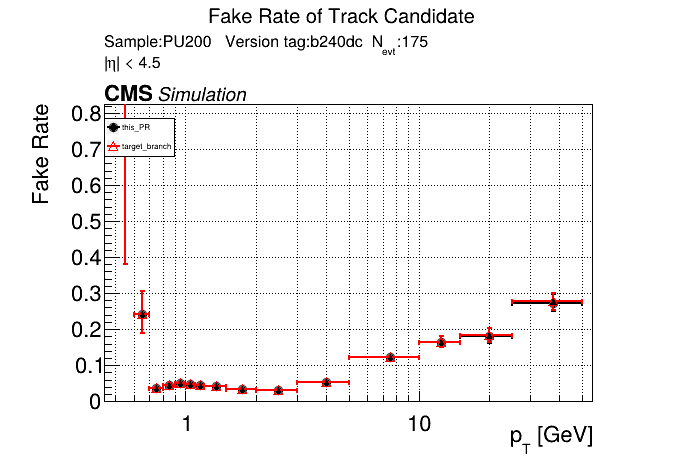
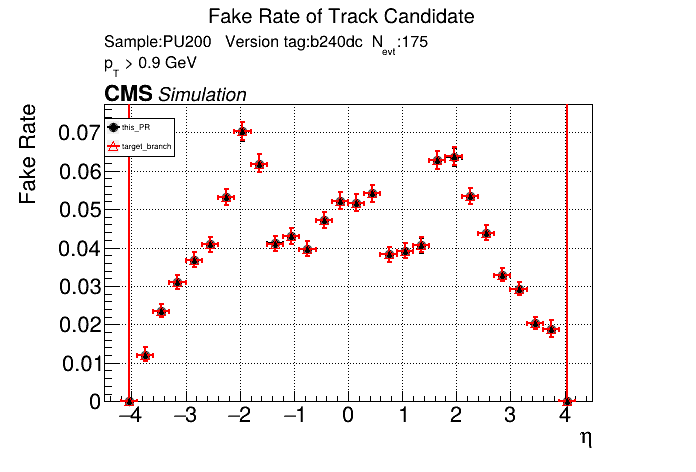
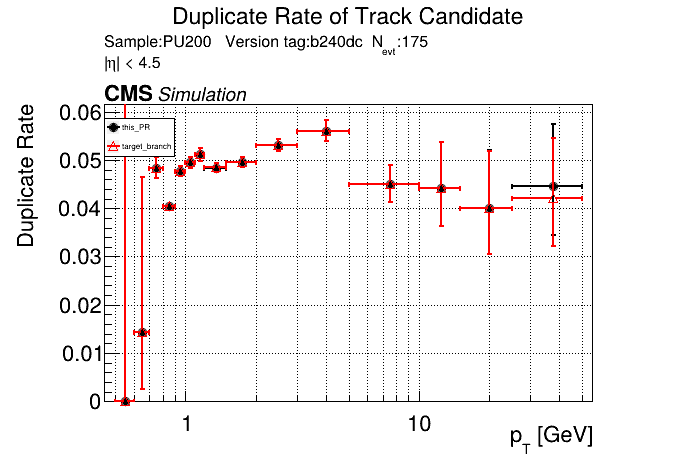
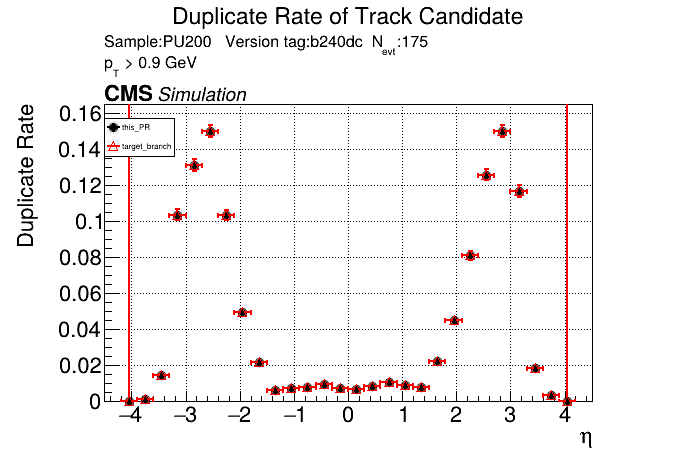
|
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
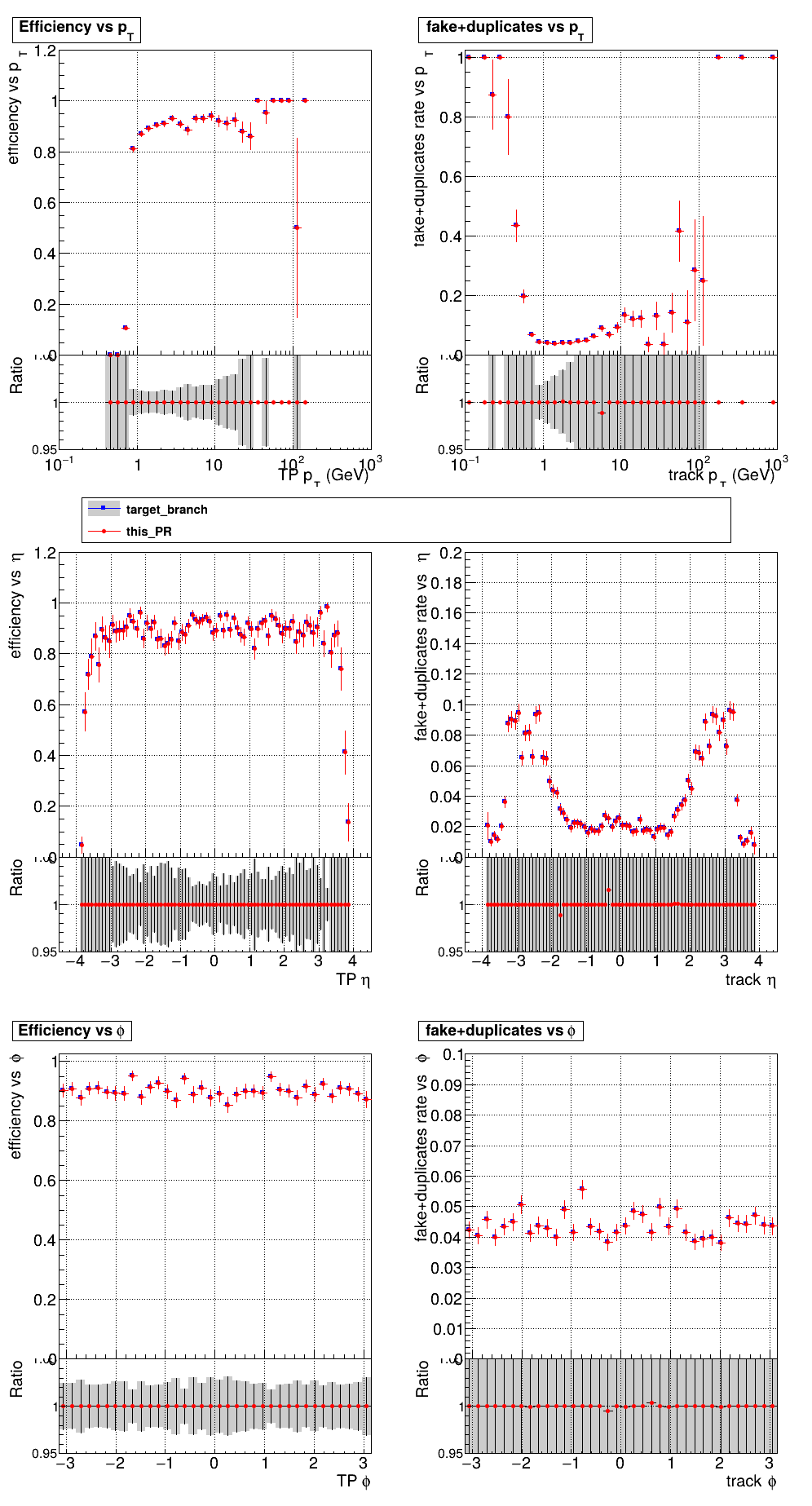
is there a way to automate extraction of the improvements by category? |
|
at least some of the comments (especially if not implemented) implied a response; is it traceable? |
Can you clarify what you mean? I've shown the timing improvement from the two segments pre-checks, I feel like most of the others are obvious (e.g. using algebraic pre-checks to avoid tan or sin calls in hot paths, using exact trig identities to reduce the number of trig calls while keeping the results exact, etc.) |
I'm asking to quantify the gains by category; or, rather to automate it (mentioned already in the earlier review, was it Monday or so). This is somewhat different from a request of proof that the gain is positive at all. |
From Mar 20:
Is this kind of workflow possible? |
I'm not sure off the top of my head. We could try to draft a few paragraphs of instructions for agents working on LST about our preferences for smaller commits, naming consistency with the rest of the codebase, etc. and see how well they follow the instructions. |
slava77
left a comment
There was a problem hiding this comment.
the main comment is related to passLooseSegmentCuts, but perhaps I'm just arguing about a part that has parallels in other precompute methods for other objects. So, changing here would only make things partially better just here.
In that case it's better to review and reuse this full/Loose selection logic in a follow up PR for other objects.
| // Algebraic: sin(atan(slope)) = |slope|/sqrt(1+slope^2), cos(atan(slope)) = 1/sqrt(1+slope^2) | ||
| float drprime_x, drprime_y; |
There was a problem hiding this comment.
| // Algebraic: sin(atan(slope)) = |slope|/sqrt(1+slope^2), cos(atan(slope)) = 1/sqrt(1+slope^2) | |
| float drprime_x, drprime_y; | |
| float drprime_x, drprime_y; // drprime * {sin,cos} (atan(slope)) | |
| // Algebraic: sin(atan(slope)) = |slope|/sqrt(1+slope^2), cos(atan(slope)) = 1/sqrt(1+slope^2) |
otherwise too much context is removed to follow what this code does
| // Algebraic dPhi pre-check: reject if sin^2(dPhi) >= looseCutDPhi^2, using Lagrange identity. | ||
| // looseCutDPhi = sdSlopeSin + sqrt(mulsAndPVoff + miniLum^2) >= sin(exact_cut) | ||
| // via sin(A+B) <= sin(A) + B, with A = asin(sdSlopeSin), B = sqrt(...). |
There was a problem hiding this comment.
the comment seems misplaced: the 10 lines below seem unrelated; move it to L563 or so
What I see below is a |dPhi| < π/2 followed by |dPhi| < π/2
| const float crossSq = crossDPhi * crossDPhi; | ||
| const float dotSq = dotDPhi * dotDPhi; | ||
|
|
||
| if (crossSq >= dotSq) |
There was a problem hiding this comment.
is taking squares and comparing them really cheaper than comparing abs values?
| const float r2sq = crossSq + dotSq; | ||
|
|
||
| if (crossSq >= looseCutDPhi * looseCutDPhi * r2sq) |
There was a problem hiding this comment.
I think I asked in another context: this looks like if (abs(crossSq) > looseCutDPhi * rtLower * rtUpper)
so the squares are not needed.
Is this really faster?
|
|
||
| const float cosSlope = alpaka::math::sqrt(acc, 1.f - sdSlopeSin * sdSlopeSin); | ||
|
|
||
| if (innerMod.subdet == Barrel && outerMod.subdet == Barrel) { |
There was a problem hiding this comment.
So, this is a loose implementation of runSegmentDefaultAlgoBarrel and runSegmentDefaultAlgoEndcap. Would it be practical to template those and if/else the approximate parts introduced here into those more general templated functions
This PR Timing (CPU) - commit 2 (pre-checks, exact trig simplifications, and additional early exits)



This PR Timing (CPU) - commit 1 (reducing redundant memory loads)
Master Timing (CPU)