面向创作者的多功能桌面端有声小说生产力工具,基于 CosyVoice 系列大模型构建,提供即开即用的文本转语音体验。
不会用?有问题? README文档可能不够详细 具体使用教程和每个页面的详情介绍和使用逻辑请参考项目Wiki页面:
https://github.com/Moeary/CosyVoiceDesktop/wiki
2026.02.14 发布 V1.5 版本,模型管理与 API 体验全升级
- 📂 模型路径智能化:
- 支持相对路径应用(
./pretrained_models),解压即用的便携体验更进一步。 - 自动路径补全:下载或设置路径时,程序会自动创建并识别
wetext和Fun-CosyVoice3-0.5B子文件夹,彻底解决路径层级问题。
- 支持相对路径应用(
- 📊 性能监测增强:
- API 运行日志新增 RTF (实时因子) 与推理耗时显示,生成性能一目了然。
- 🎨 UI 细节优化:
- 模型下载页面重构:支持独立设置 WeText 和 CosyVoice 路径,并显示已下载状态 (✅/⬜)。
- 移除了启动时的 QFluentWidgets Pro 购买提示弹窗。
- 修复了 API 重启后日志重复输出的 Bug。
2025.12.30 发布V1.4版本,API服务与UI交互大升级
- 🔌 API服务上线:内置本地 TTS API 服务,适配SillyTavern(酒馆),并支持通过第三方油猴脚本对接Pixiv/爱丽丝书屋等在线小说阅读平台。
- 🎨 UI交互大升级:
- 侧边栏新增 GitHub 仓库直达与工具提示。
- 语音设置与任务计划列表支持列宽自由拖动,操作更顺手。
- API 日志支持自适应主题配色,深浅色模式下均清晰可见。
- 🛠️ 体验优化:
- 启动 API 服务时若未加载模型,将自动触发模型加载,无需手动操作。
- 优化了日志输出,去除冗余信息,专注核心推理状态。
2025.12.16 发布V1.3版本,升级至CosyVoice3,便携包提供两种模式,github里面的压缩包不再打包预训练模型(节省一下体积),百度网盘里面的带预训练模型,以后考虑将所有的发布版本都迁移到github里面去,就再也不用受百度网盘的压迫了
- 🚀 升级到CosyVoice3-0.5b:全新的语音生成模型,语音质量与情感表达能力大幅提升
- 📥 灵活的模型下载:内置「模型下载」页面,支持 HuggingFace 和 ModelScope 两种下载渠道,并显示下载进度
- 🎵 新增语音修补模式:支持四种模式 - 零样本复制、精细控制、指令控制、语音修补(hotfix)
2025.12.14 发布V1.2版本,torch环境更新到torch2.7.0+cu128 理应支持50系显卡了
- ✨ UI优化:新增"设置"页面,支持主题切换(浅色/深色/自动)
- 🎵 模式简化:仅保留"零样本复制""精细控制""指令控制"三种推理模式,移除"流式输入"
- 💾 配置记忆:启动时自动加载上次使用的语音配置和项目设置,无需手动点击"应用"按钮
- 📁 输出目录优化:音频自动保存到
output/{ProjectName}/目录,便于项目分类管理
2025.10.31 主要更新README文档和Asset文件夹 程序本身没太大实质性变化 根据Issue2的问题反馈添加演示示例视频 于Readme下方可以查看,同时asset文件夹下添加更多示例音频数据(大部分来源于【1080p+修复/国语】精灵宝可梦:无印篇第1集 自行剪辑获得 如有侵权我将立马删除)以供多角色朗读测试使用
2025.10.30 根据Issue反馈缺失Pillow库重新打包上传上传V1.1版本,可以于百度网盘下载最新的一键包,不想重下的也可以下载site-package.zip压缩包根据txt提示将文件解压到制定路径即可使用
2025.10.7 上传V1.0版本
CosyVoice Desktop 是在官方 CosyVoice 能力之上构建的图形化有声内容创作平台。通过 PyQt5 与 Fluent Design 风格界面,整合零样本克隆、精细控制、指令式创作等多种推理模式,帮助小说、广播剧、播客及教育内容创作者快速完成高质量的有声作品。
- 一站式工作流:从文本管理、角色配置到批量音频导出均在同一界面完成。
- 四种语音模式:零样本克隆、精细控制、指令控制、语音修补,覆盖旁白/人物/方言转换需求。
- 智能配置记忆:启动时自动加载上次使用的语音配置和项目设置,提升工作效率。
- 色彩化标注体验:不同角色以颜色区分,提升长篇文本的配音效率与可读性。
- 自动化播放与日志:生成后自动按段播放并输出实时日志,快速定位问题。
- 配置复用:支持语音配置保存/导入,多端协同创作毫不费力。
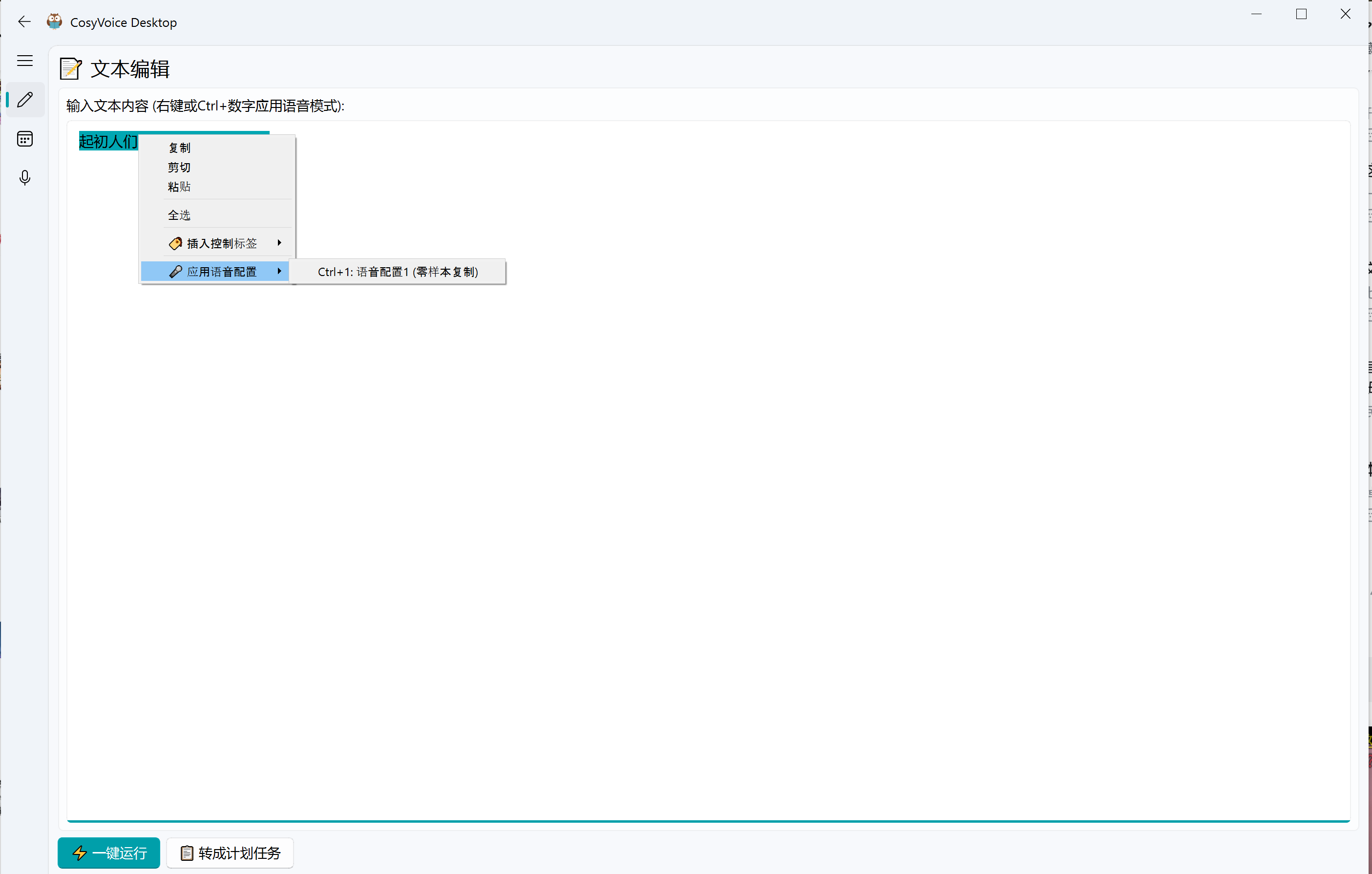
- 智能文本编辑器,支持复制/粘贴/剪切/撤销等常用操作。
- 按段落为文本绑定语音配置,实时查看配音颜色标记。
- 一键生成后自动顺序播放音频,历史记录清晰可追溯。
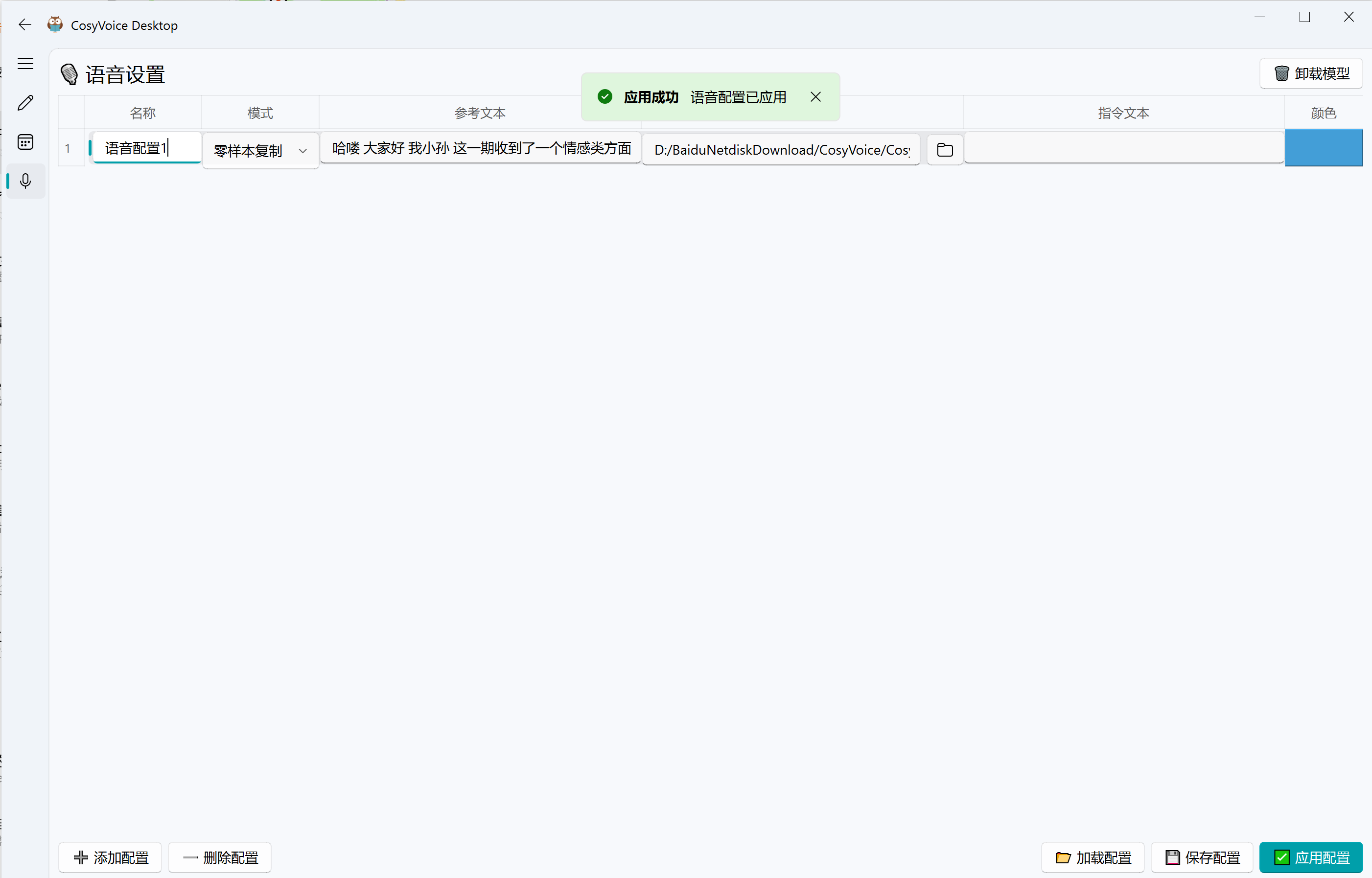
- 支持无限量语音配置,适配旁白、主要角色、群演等场景。
- 配置项包含模式(零样本/精细控制/指令控制/语音修补)、参考文本、参考音频与标记颜色。
- 启动时自动加载上次使用的语音配置,无需重复设置。
- JSON 导入导出,可与团队成员共享同一套角色库。
- 支持中文、英文、日文、韩文及多种方言的跨语言与风格转换需求。
- 日志面板实时展示生成进度、耗时与潜在告警信息。
- 输出目录自动管理生成文件(按项目分类),支持批量回放与二次处理。
- 主题切换功能,支持浅色/深色/自动三种模式。
V1.4 新增标准 HTTP API 支持,可将 CosyVoice 能力集成到其他应用中。
- 一键启动:在 "API 服务" 页面点击启动即可,支持自动加载模型。
- 酒馆适配:完美支持 SillyTavern (酒馆) 的 TTS 接口,支持角色列表获取。
- 小说朗读:支持通过 Tampermonkey (油猴) 脚本对接 Pixiv、爱丽丝书屋等网站,实现浏览器内直接朗读。
- 接口文档:启动服务后,点击界面上的 "?" 按钮即可查看完整 API 文档。
从 v1.3 开始,程序不再提供打包的模型文件。请根据以下步骤下载所需模型:
- 启动程序后,打开侧边栏 模型下载 页面
- 选择下载渠道:
- 1. HuggingFace - 推荐,如有网络问题可选择 2
- 2. ModelScope - 国内用户推荐,如 HuggingFace 下载困难
- 点击 一键下载默认模型,程序将自动下载以下模型到
pretrained_models/目录:wetext/- 文本标准化模型Fun-CosyVoice3-0.5B/- CosyVoice3 推理模型
- 下载过程中可在页面内查看日志与进度条,下载完成后模型路径会自动更新
如需更细化控制,可在命令行运行:
python core/download.py --help支持的选项:
--all下载全部模型(默认)--wetext仅下载 wetext--cosyvoice3仅下载 CosyVoice3--method huggingface|modelscope指定下载渠道
| 方式 | 推荐人群 | 前置条件 | 快速操作 |
|---|---|---|---|
| 方式一:Github/百度网盘一键包 | 想立即体验、拥有 NVIDIA GPU 的创作者(实际上使用CPU也可以跑) | 支持 CUDA ≥ 12.8 的 NVIDIA 显卡,Windows 10/11 | 下载压缩包 → 解压 → 双击bat运行程序 |
| 方式二:已有 CosyVoice 环境 | 已经本地部署官方 CosyVoice 的用户 | 本地 CosyVoice 目录与模型完整可用 | 安装桌面依赖 → 运行 python main.py |
🔔 提示:两种方式可并行维护,推荐保留同一套
pretrained_models以节省磁盘空间。
- 需要最快上手体验 CosyVoiceDesktop 的创作者。
- 设备搭载 NVIDIA GPU,驱动已支持 CUDA 12.8 及以上版本。
- 或者设备拥有一颗强力的CPU和足够高的内存带宽可以使用CPU来跑,此时就不需要考虑NVIDIA 显卡了
- Windows 10/11 环境。
- 访问github release界面或者百度网盘链接下载压缩包:
- GitHub 推荐版:仅含代码+环境,体积较小,需自行下载模型
- 百度网盘完整版:包含预训练模型,开箱即用,体积较大
- 在本地磁盘解压,例如
D:\CosyVoiceDesktop。 - 检查显卡驱动与 CUDA Runtime 是否满足 12.8 及以上要求。
- 首次启动后进入程序内的「模型下载」页面下载模型(如果是完整版可跳过此步)。
- 再双击运行
StartCosyVoice.bat启动程序。 - 进入主界面参考教程使用即可。
- asset/: 存放测试音频文件,如
孙笑川_哈喽 大家好 我小孙 这一期收到了一个情感类方面比较抽象的一个粉丝 发来这个东西 而且他说了 这个东西是绝对属实的,用于快速实验测试,省去自行查找音频片段。 - config/: 人物语音配置目录,用于存放工程对应的配置文件(json格式,记录命名和参考音频文件,自动保存且启动时自动加载)。
- cosyvoice/、pretrained_models/、python_env/、third_party/: 核心项目文件,无需移动或修改。
- output/: 默认的音频输出目录,自动按项目名称创建子文件夹(output/{ProjectName}/ ),用于保存生成的音频文件,便于项目分类管理。
- 解压路径请避免中文或空格字符,以免影响 Python 虚拟环境。
- 若 Windows SmartScreen 拦截,可选择“更多信息 → 仍要运行”。
- 在首次运行时加载大型模型时耗时较长,耐心等待日志面板提示完成。
- 已在本地
CosyVoice源码目录中完成依赖安装与模型下载。 - 希望直接将 GUI 集成至现有环境,保持与官方脚本同一套虚拟环境(使用pixi管理的前提下)。
- 切换至 CosyVoice 根目录:
cd path\to\CosyVoice
- 确保虚拟环境已激活且可正常运行官方脚本。
- 安装桌面端依赖:
pixi install
- 将
CosyVoiceDesktop仓库中的main.py和core文件夹以及ui文件夹 复制到 CosyVoice 根目录或自定义工作目录: - 运行桌面应用:
pixi run start
- 终端开启API服务(可选):
pixi run api
CosyvoiceDesktop_Demo_AV1.mp4
- 打开语音设置页面,创建或导入角色配置,选择参考音频并点击"应用配置"(后续启动会自动加载)。
- 切换到文本编辑页面,输入或粘贴待合成文本,通过快捷键(Ctrl+数字)或右键工具菜单为不同段落分配语音配置(不同颜色标记)。
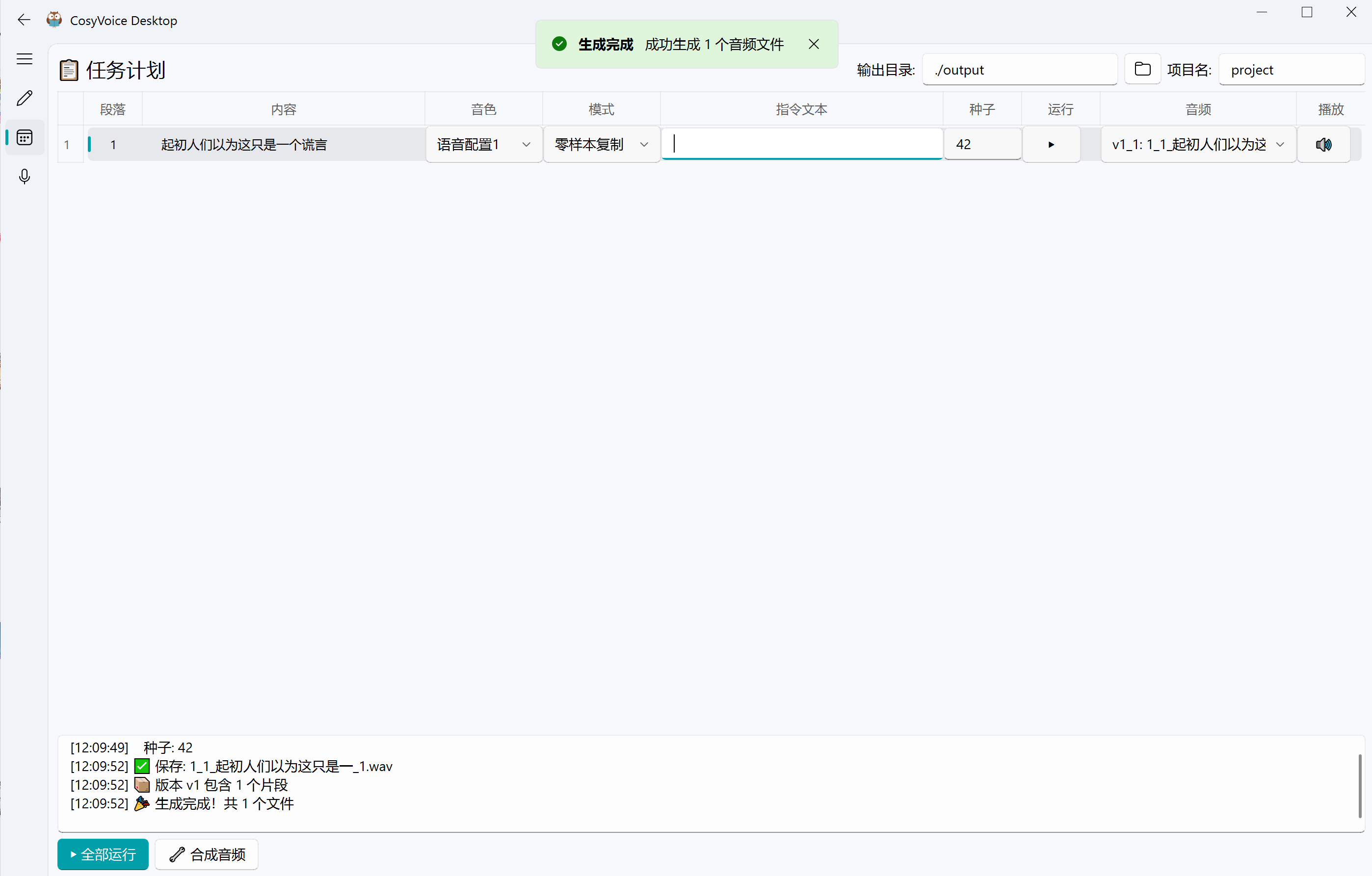
- 点击一键运行(或将任务转换为计划任务),切换到计划任务页面,查看任务执行日志和输出。
- 若合成效果不满意,可在计划任务页面点击"三角形运行按钮"进行重Roll。
- 所有段落合成完成后,点击"合成音频"按钮(需要ffmpeg环境),将分段音频合并为完整音频文件。
-
应用启动时自动加载配置: V1.2版本新增配置记忆功能,应用启动时会自动加载上次保存的语音配置,无需点击"应用配置"按钮。若想切换配置,可在语音设置页面加载不同的配置文件。
-
No module named 'PIL': 这是由于一键包在打包过程中遗漏了
Pillow库导致的,我们计划在下个一键运行包版本中修复。目前您可以根据以下任一方法手动解决: 问题根源 程序使用的是自带的便携 Python 环境 (python_env),而部分用户电脑上通过pip install Pillow命令会将库安装到系统默认的 Python 环境中,导致程序无法找到。 解决方案 1:手动复制文件- 找到系统库位置:进入您系统 Python 的包目录,例如
C:\Users\Administrator\AppData\Local\Programs\Python\Python313\Lib\site-packages。 - 复制文件夹:在该目录中找到
PIL和Pillow-X.X.X.dist-info(版本号可能不同) 两个文件夹,并复制它们。 - 粘贴到程序环境:将这两个文件夹粘贴到本程序的便携环境目录中:
{解压缩后的文件夹目录}\python_env\Lib\site-packages。
解决方案 2:使用命令行强制安装 (推荐)
- 打开程序的根目录(即
StartCosyVoice.bat所在的文件夹)。 - 在文件夹顶部的地址栏输入
cmd并按回车,打开终端。 - 复制并执行以下命令:
python_env\Scripts\pip.exe install Pillow --upgrade
完成以上任一操作后,重新运行
StartCosyVoice.bat即可。 - 找到系统库位置:进入您系统 Python 的包目录,例如
-
合成音频失败: 这通常是因为系统中缺少
ffmpeg环境。- 解决方案:请自行搜索并下载
ffmpeg,并将其路径配置到系统的环境变量Path中。 - 提示:一键合成功能主要用于快速预览。对于对话场景,合成后的单音频可能效果不佳,建议将
output文件夹中生成的分段原始音频导入剪辑软件进行精细调整。
- 解决方案:请自行搜索并下载
-
模型加载失败:确保
pretrained_models中的目录与配置指向一致,且显存足够(建议 ≥ 4 GB)。 -
界面空白或闪退:确保已安装最新显卡驱动,必要时以管理员权限运行。
-
音频无声或失真:核对参考音频语言与文本语言是否匹配(尤其是在零样本模式下,不能以日语参考音频来推理出中文音频)。
- 项目主页
- 功能需求与问题反馈:请在 GitHub Issues 提交
- 本项目基于 CosyVoice 开源能力,遵循原项目许可证及使用规范。请在下载和部署前阅读并遵守 CosyVoice 官方条款。
- 用户在创作过程中应确保拥有使用输入文本、参考音频及生成内容的合法权利,不得侵犯第三方的版权、肖像权或其他合法权益。
- 禁止将本项目用于任何违法、违规或违背公共秩序与善良风俗的用途;如因违规使用导致损失,责任由用户自行承担。
- 项目提供的打包版本及脚本仅供个人学习与研究使用,未经许可不得用于商业再发行或转售。
- 项目维护者保留依据法律法规或社区反馈随时更新、暂停或终止服务与支持的权利。
使用 CosyVoiceDesktop 即视为同意上述协议条款。若您不同意任何条款,请立即停止使用并删除相关文件。