Les modèles les plus appropriés pour créer une IA capable de répondre à des questions sur le logiciel Soins2000 semblent être :
- Ministral 8B
- Ministral 3B
- Open Mistral Nemo
Ne surtout pas utiliser magistral-medium, je n’ai obtenu que de mauvais résultats.
La méthode appropriée pour la compréhension de la documentation n’est pas le fine-tuning mais le RAG (Retrieval-Augmented Generation). Référez-vous à cette page : https://docs.mistral.ai/guides/rag/
Cependant, le fine-tuning peut être utilisé en complément du RAG pour affiner la forme et le format des réponses. Voir Fine-tuning
Dans ce dépôt, vous trouverez les outils suivants :
- Un outil en Python permettant de benchmarker les modèles Mistral et de produire un compte rendu au format Markdown.
- Un chatbot Python exploitant le principe du RAG. Il commence par convertir la documentation en vecteurs, qu’il stocke ensuite dans une base spécialisée (Faiss). Lorsqu’un utilisateur pose une question, celle-ci est à son tour transformée en vecteurs pour rechercher les passages les plus pertinents dans la base. Le contenu trouvé est alors fourni comme contexte au modèle afin de générer une réponse adaptée.
- Un client en C++ qui envoie les requêtes des utilisateurs à un serveur et reçoit les réponses.
- Un serveur en C++ qui reçoit les questions, s'occupe du RAG, puis de la génération du prompt pour finir par envoyer le prompt à l’API Mistral avant de renvoyer la réponse au client.
- Une api en python permettant d'intégrer le système simplement dans n'importe quel programme.
- Une api en c++ permettant d'intégrer le système simplement dans n'importe quel programme.
Le client/serveur en C++ fournit de moins bonnes réponses que le ChatBot Python. Cela vient, je pense, de la méthode RAG qui est différente.
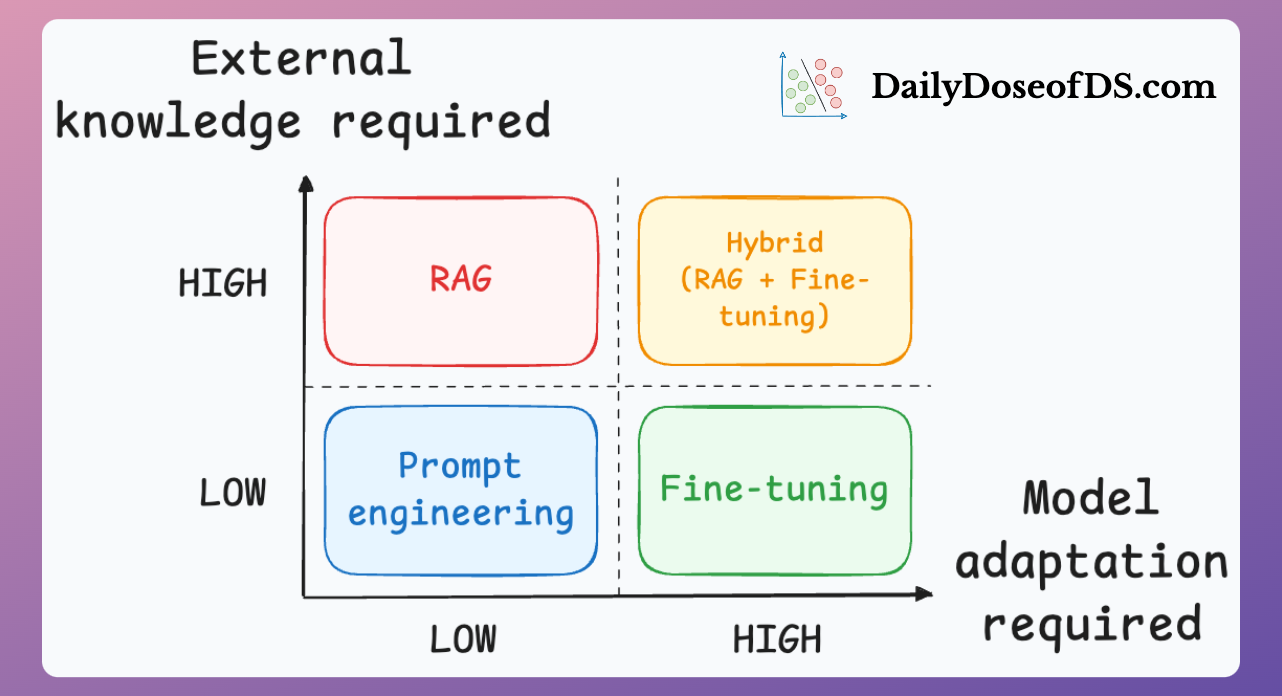
Réentraîner le modèle sur des données spécifiques pour qu’il adopte un ton, un style ou un savoir-faire particulier.
Connecter le modèle à une base documentaire externe pour qu’il aille chercher des informations à jour avant de répondre.
Formuler des instructions précises pour orienter la réponse du modèle dans la bonne direction.
Prompting Guide
Utilisés ensemble, ces trois leviers permettent d’exploiter le plein potentiel d’un modèle IA.
Le fine-tuning lui donne une personnalité ou une spécialisation métier, le RAG garantit que ses réponses s’appuient sur des données fiables et récentes, et le prompting affine en temps réel la forme et le fond de la sortie.
Cette combinaison crée un assistant intelligent, pertinent et réactif, capable de s’adapter à la fois au contexte, à l’actualité et aux besoins de l’utilisateur.
La finalité de ce stage est l'api en C++ qui pourrait vous permettre d'implémenter facilement et rapidement cet ia en envoyant simplement une requete POST, cette solution est la plus légère possible pour le client, tous est gérer par le serveur de l'api.
Je tiens à remercier chaleureusement toute l’équipe de Soins2000 pour l’accueil et la bienveillance dont vous avez fait preuve tout au long de mon stage. Ce fut une expérience enrichissante et motivante, et je suis très reconnaissant(e) d’avoir pu travailler à vos côtés.
Je porte votre attention sur le fait que ce repo peut être imcomplet, j'ai exploré plusieurs méthode différentes pendant ce stage, également les programme donné ne sont pas optimisés et ne suivent aucune norme de cyber-sécurité, api sans authentification, communication en http et non en https etc...