public class Main {
public static void main(String[] args) {
Thread t = new MyThread();
t.start(); // 启动新线程
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("start new thread!");
}
}
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 启动新线程
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
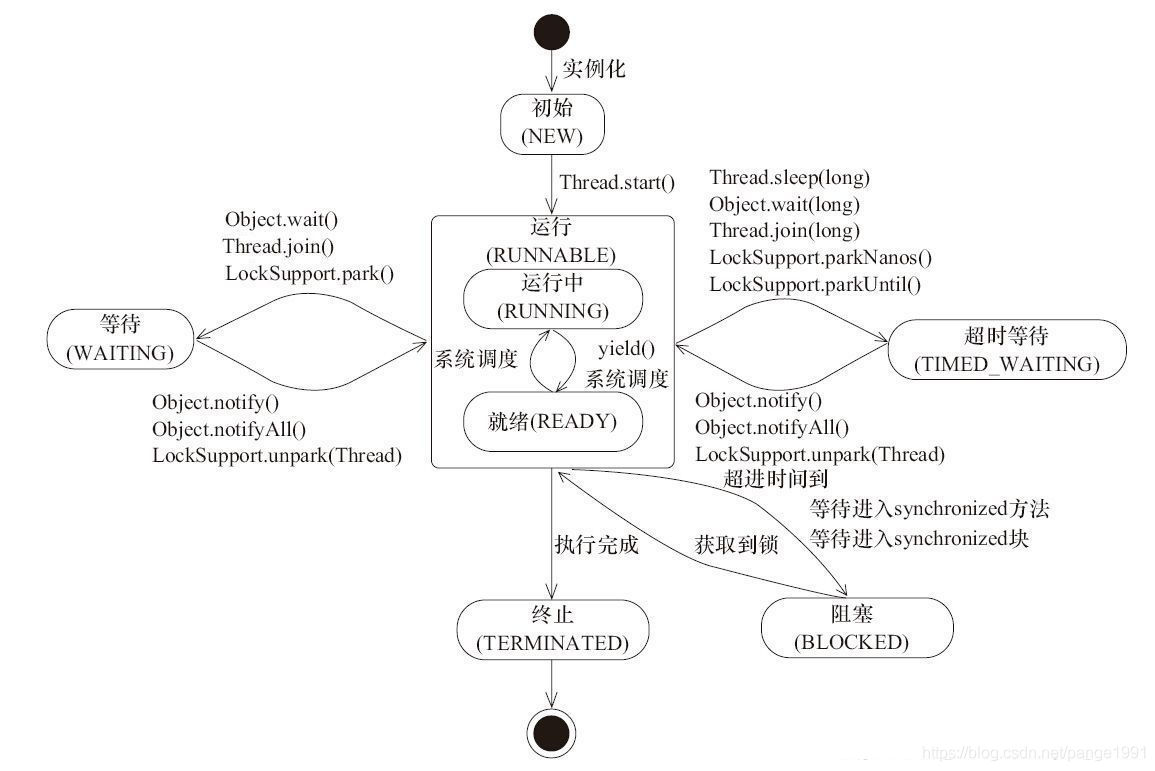
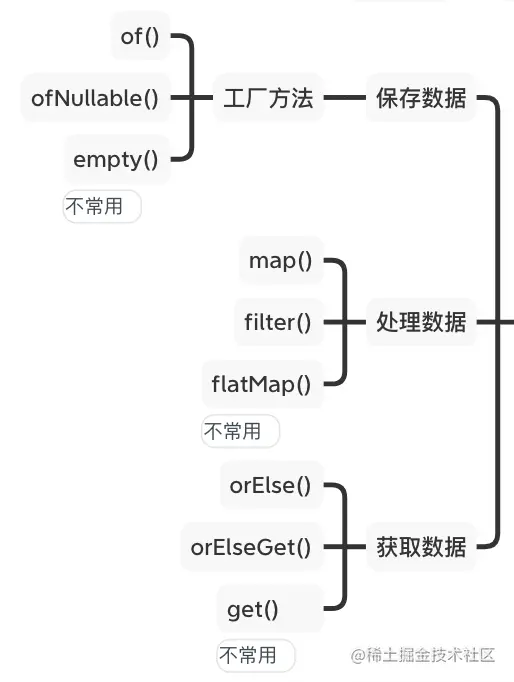
1、初始状态(NEW) 实现Runnable接口和继承Thread可以得到一个线程类,new一个实例出来,线程就进入了初始状态。
2、就绪状态(RUNNABLE之READY) 就绪状态只是说你资格运行,调度程序没有挑选到你,你就永远是就绪状态。 调用线程的start()方法,此线程进入就绪状态。 当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。 当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。 锁池里的线程拿到对象锁后,进入就绪状态。 3、运行中状态(RUNNABLE之RUNNING) 线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一的一种方式。
4、阻塞状态(BLOCKED) 阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
5、等待(WAITING) 处于这种状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。
6、超时等待(TIMED_WAITING) 处于这种状态的线程不会被分配CPU执行时间,不过无须无限期等待被其他线程显示地唤醒,在达到一定时间后它们会自动唤醒。
7、终止状态(TERMINATED) 当线程的run()方法完成时,或者主线程的main()方法完成时,我们就认为它终止了。这个线程对象也许是活的,但是它已经不是一个单独执行的线程。线程一旦终止了,就不能复生。
1、使用退出标志
通过标志位判断需要正确使用volatile关键字
2、使用 interrupt 方法
一个线程在未正常结束之前, 被强制终止是很危险的事情. 因为它可能带来完全预料不到的严重后果比如会带着自己所持有的锁而永远的休眠,迟迟不归还锁等。 所以你看到Thread.suspend, Thread.stop等方法都被Deprecated了
那么不能直接把一个线程搞挂掉, 但有时候又有必要让一个线程死掉, 或者让它结束某种等待的状态 该怎么办呢?一个比较优雅而安全的做法是:使用等待/通知机制或者给那个线程一个中断信号, 让它自己决定该怎么办。
对目标线程调用interrupt()方法可以请求中断一个线程,目标线程通过检测isInterrupted()标志获取自身是否已中断。如果目标线程处于等待状态,该线程会捕获到InterruptedException
目标线程检测到isInterrupted()为true或者捕获了InterruptedException都应该立刻结束自身线程
interrupt方法可以终止运行态的线程吗?
public class ThreadInterrupt {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
t.interrupt();
}
//打印线程
public static class MyThread extends Thread{
@Override
public void run() {
int i=0;
while(true){
i++;
System.out.println("run:"+i);
}
}
}
}
我们发现,打印线程会一直运行下去,interrupt方法并不能终止运行的线程本身。
线程处于sleep状态,被中断
public class ThreadInterrupt {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
t.interrupt();
}
public static class MyThread extends Thread{
@Override
public void run() {
int i=0;
while(true){
i++;
System.out.println("run:"+i);
try {
sleep(5000);
} catch (InterruptedException e) {
System.out.println("被中断,返回");
break;
}
}
}
}
}
使用interrupted方法和isInterrupted方法
public class ThreadInterrupt2 {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
t.interrupt();
}
public static class MyThread extends Thread{
@Override
public void run() {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("我进入了中断线程的条件中,将要结束run方法");
break;
} else {
System.out.println("我没有收到中断信息");
}
}
}
}
}
1、用法
(1)修饰一个方法,对当前实例对象加锁
在定义接口方法时不能使用synchronized关键字。 构造方法不能使用synchronized关键字,但可以使用synchronized代码块来进行同步。 synchronized 关键字不能被继承 ,如果要同步需要显式的加上关键字。 synchronized 关键字修饰的方法如果被重写默认不同步,如果要同步需要显式的加上关键字,或者super父类的方法也就相当于同步了。
public class Synchronized {
public synchronized void husband(){
}
}
(2)修饰静态方法
静态方法是属于类的而不属于对象的 。同样的, synchronized修饰的静态方法锁定的是这个类的所有对象,所有类用它都会有锁的效果。
public synchronized static void method() {
// todo
}
(3)修饰一个类
因为Class数据存在于永久代,因此静态方法锁相当于该类的一个全局锁
其作用的范围是synchronized后面括号括起来的部分,作用的对象是这个类的所有对象,只要是这个类型的class不管有几个对象都会起作用。
public class Synchronized {
public void husband(){
synchronized(Synchronized.class){
}
}
}
(4)修饰代码块
synchronized(this)锁的是当前对象,当前有几个对象那么这个this就是有多份,这里的this只能锁同一个对象。
public class Synchronized {
public void husband(){
synchronized(this){
}
}
}
2、原理
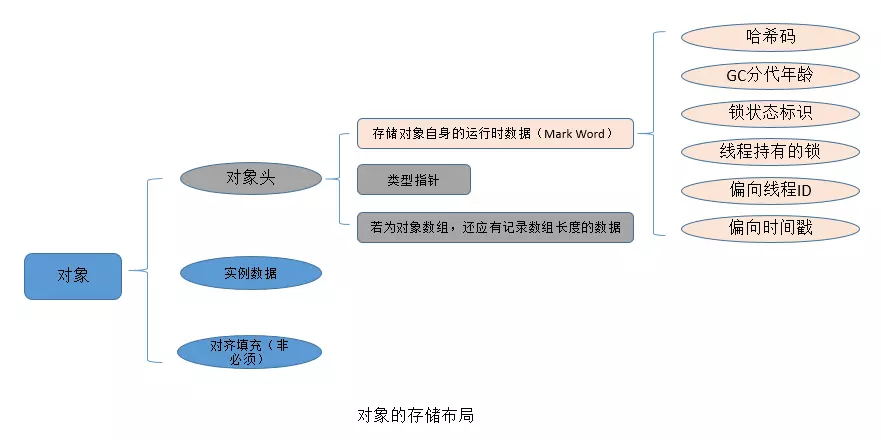
在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
对象头:Java对象头一般占有2个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit,在64位虚拟机中,1个机器码是8个字节,也就是64bit),但是 如果对象是数组类型,则需要3个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。

(1)无锁状态

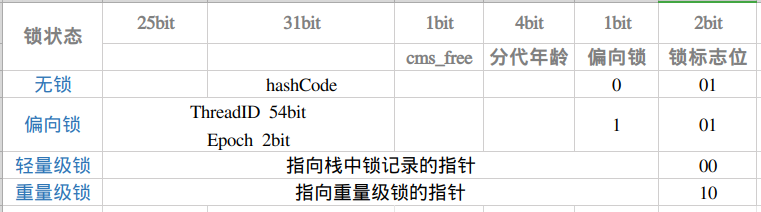
Java 对象刚创建时,还没有任何线程来竞争,说明该对象处于无锁状态(无线程竞争它)这偏向锁标识位是 0、锁状态 01
(2)偏向锁
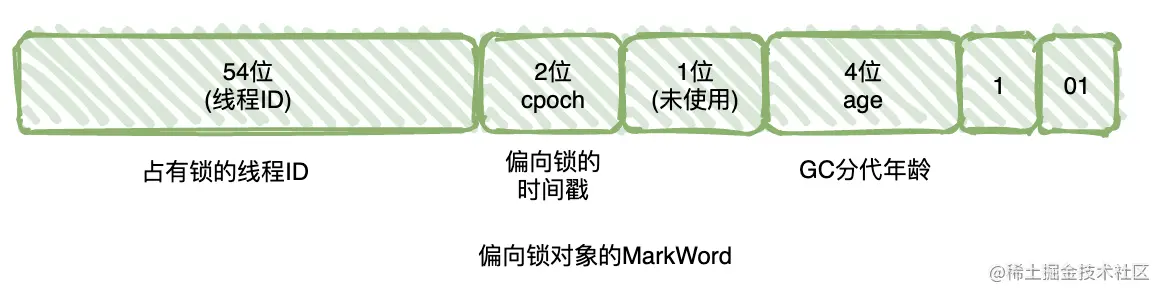
偏向锁是指一段同步代码一直被同一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价,如果处于偏向状态,对象的markWord会存储该偏向线程的线程id,注意这里的线程Id并不是我们通过Thread.currentThreadId(),而是操作系统分配的内置的线程id,当偏向的线程执行同步代码块时,只需要判断对象头中存储的线程id是不是当前线程id就可以,所以代价非常小。
(3)轻量级锁

当有两个线程开始竞争锁对象时,情况发生变化,不在是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,那个线程先占有锁对象,锁对象的MarkWord就指向了那个线程的栈帧的锁记录。企图获取锁的线程会通过自旋的形式获取锁,JVM不会阻塞抢占锁的线程,避免了用户线程从用户态切换到内核态的消耗。
自旋是消耗CPU资源的,如果一直获取不到锁,线程会一直做没有意义的CPU自旋,所以,需要设定一个最大的自旋等待时间,JVM引入了自适应自旋锁,自旋的时间是不固定的,而是有前一次在该锁上线程自旋时间以及锁的拥有者状态决定,如果线程自旋成功,那么下次自旋的字数会更多,如果自旋失败,则下次的自旋次数就会减少。
(4)重量级锁

如果持有锁的线程执行的时间超过最大等待时间仍没有释放锁,那么就会导致其他正在等待获取锁的线程在最大等待时间还是获取不到锁,此时,自旋就不会一直持续下去,这时,JVM会停止线程自旋,将参与自旋的线程挂起,锁膨胀微重量级锁。
重量级锁会让其他申请的线程直接进入阻塞,因为涉及到用户线程从用户态,切换到内核态,所以性能降低,重量级锁也叫同步锁这个锁对象的MarkWord会指向一个监视器Monitor对象,该对象用集合的形式来登记和管理排队的线程。
(5)流程
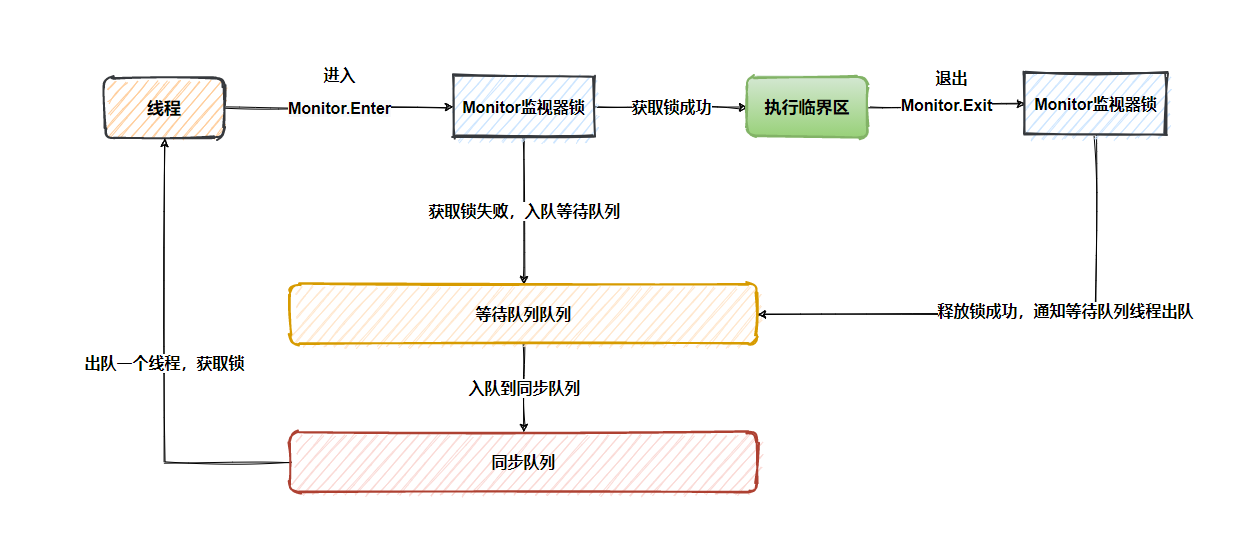
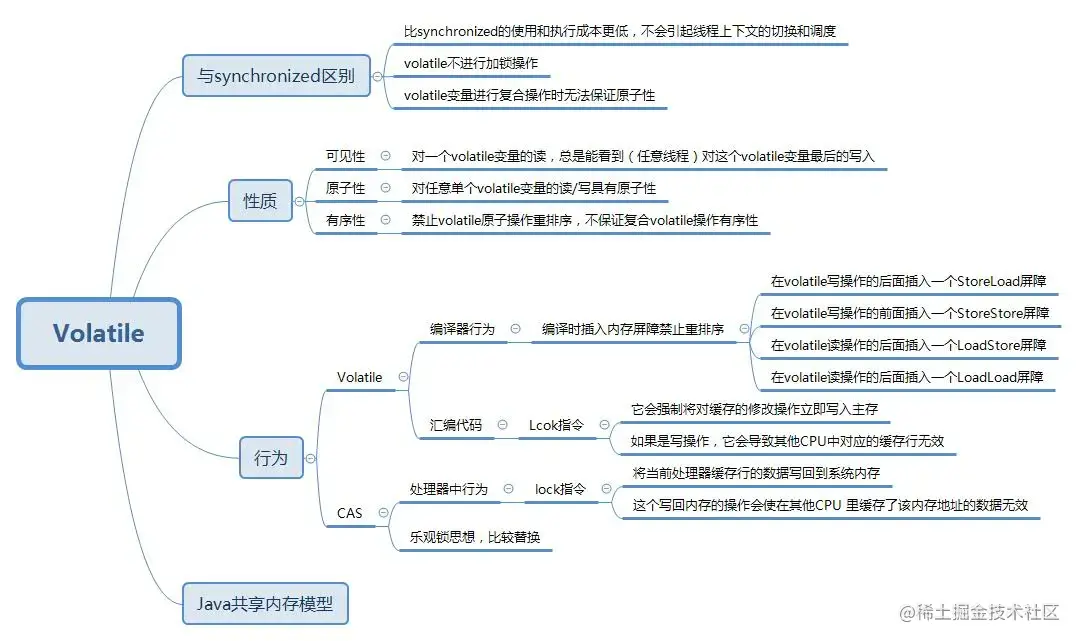
1、性质
(1)可见性
Java虚拟机规范中定义了一种Java内存 模型(Java Memory Model,即JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果。Java内存模型的主要目标就是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的细节。
JMM中规定所有的变量都存储在主内存(Main Memory)中,每条线程都有自己的工作内存(Work Memory),线程的工作内存中保存了该线程所使用的变量的从主内存中拷贝的副本。线程对于变量的读、写都必须在工作内存中进行,而不能直接读、写主内存中的变量。同时,本线程的工作内存的变量也无法被其他线程直接访问,必须通过主内存完成。
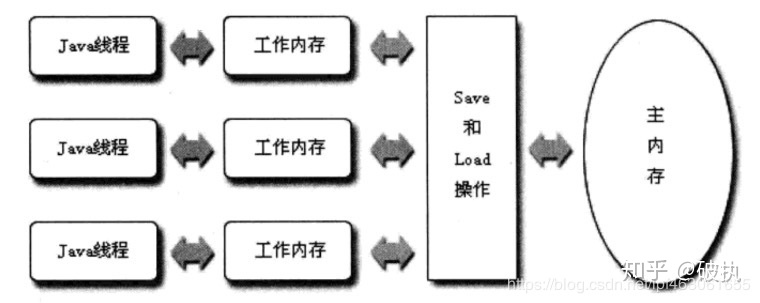
对于普通共享变量,线程A将变量修改后,体现在此线程的工作内存。在尚未同步到主内存时,若线程B使用此变量,从主内存中获取到的是修改前的值,便发生了共享变量值的不一致,也就是出现了线程的可见性问题。
使用了volatile:当对volatile变量执行写操作后,JMM会把工作内存中的最新变量值强制刷新到主内存,并且写操作会导致其他线程中的缓存无效。
(2)有序性
指令重排序是JVM为了优化指令,提高程序运行效率,在不影响单线程程序执行结果的前提下,尽可能地提高并行度。但是在多线程环境下,有些代码的顺序改变,有可能引发逻辑上的不正确。有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们的程序的性能就堪忧了,所以合理的方案是按需禁用缓存或者编译优化。
volatile的有序性是通过内存屏障来保证的
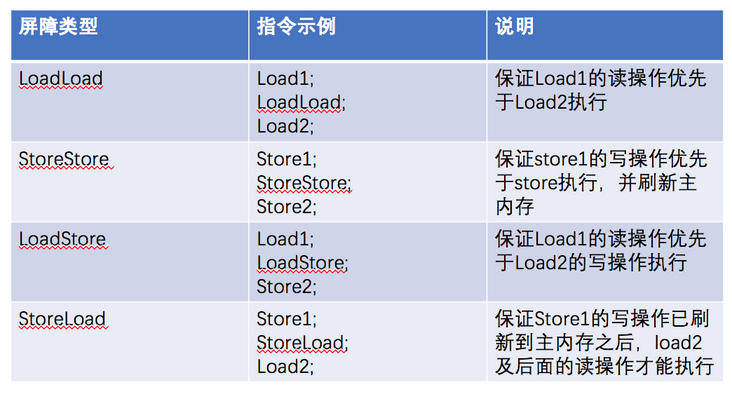
对于volatile的写操作,在其前后分别加上 StoreStore 和 StoreLoad指令
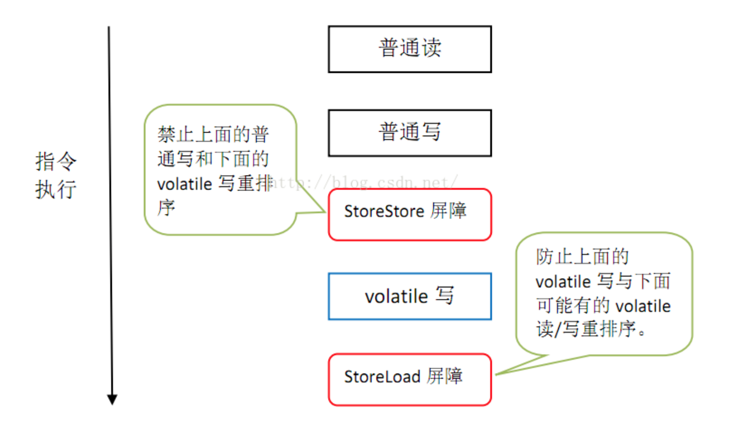
对于volatile的读操作,在其后加上 LoadLoad 和 LoadStore指令
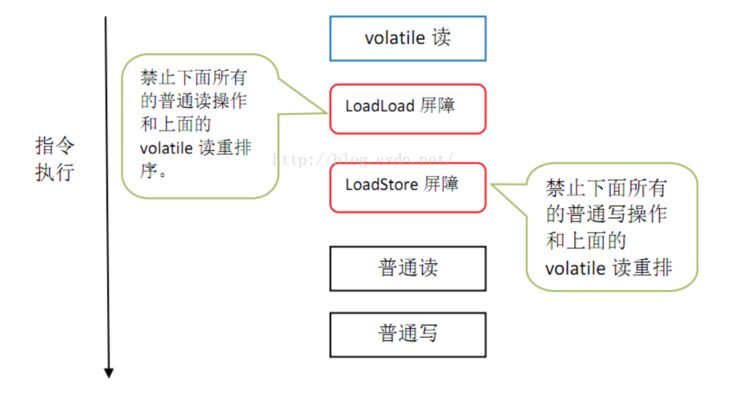
(3)原子性
只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
2、修改volatile变量流程
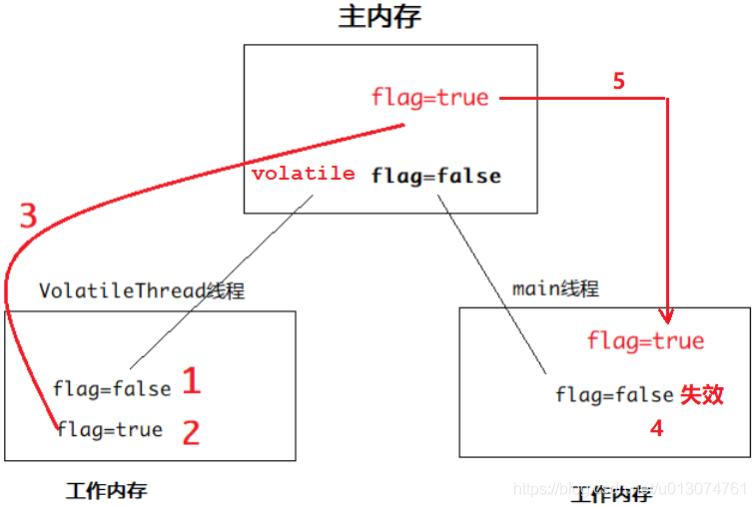
(1)读取volatile变量到local
(2)修改变量值
(3)local值写回
(4)插入内存屏障,即lock指令,让其他线程可见
wait(long,int):对于超时时间更细力度的控制,单位为纳秒。
notify():随机唤醒等待队列中等待同一共享资源的一个线程,并使该线程退出等待队列,进入可运行状态,也就是notify()方法仅通知一个线程。
notifyAll():使所有正在等待队列中等待同一共享资源的全部线程退出等待队列,进入可运行状态。此时,优先级最高的那个线程最先执行,但也有可能是随机执行,这取决于JVM虚拟机的实现。
join:等待目标线程执行完成之后再继续执行
yield:线程礼让。目标线程由运行状态转换为就绪状态,也就是让出执行权限,让其他线程得以优先执行,但其他线程能否优先执行是未知数
sleep和wait的区别
当线程执行sleep方法时,不会释放当前的锁(如果当前线程进入了同步锁),也不会让出CPU。sleep(milliseconds)可以用指定时间使它自动唤醒过来,如果时间不到只能调用interrupt方法强行打断。
当线程执行wait方法时,会释放当前的锁,然后让出CPU,进入等待状态。只有当notify/notifyAll被执行时候,才会唤醒一个或多个正处于等待状态的线程,然后继续往下执行,直到执行完synchronized代码块的代码或是中途遇到wait() ,再次释放锁。
Thread.Sleep(0)的作用是“触发操作系统立刻重新进行一次CPU竞争”
notify/notifyAll的执行只是唤醒沉睡的线程,而不会立即释放锁,必须执行完notify()方法所在的synchronized代码块后才释放。所以在编程中,尽量在使用了notify/notifyAll()后立即退出临界区。
TSL是Test and Set Lock的缩写,是CPU提供的一个原子指令,其工作如下所述:它将一个存储器字读到一个寄存器中,然后在该内存地址上存一个非零值。读数和写数操作保证是不可分割的——即该指令结束之前其他处理机均不允许访问该存储器字。执行TSL指令的CPU将锁住内存总线(实际是锁缓存)以禁止其他CPU在本指令结束之前访问内存。操作系统的Mutex的加锁过程就是基于TSL指令实现的。
CAS是Compare and Swap的缩写,又叫比较并交换,是一种无锁算法,日常开发中,基本不会直接用到CAS,都是通过一些JDK封装好的并发工具类来使用的。
public class CASTest {
static int i = 0;
public synchronized static void increment() {
i++;
}
}
使用cas代替 synchronized 对方法的加锁:
1、线程从内存中读取 i 的值,假如此时 i 的值为 0,我们把这个值称为 k 吧,即此时 k = 0。 2、令 j = k + 1。 3、用 k 的值与内存中i的值相比,如果相等,这意味着没有其他线程修改过 i 的值,我们就把 j(此时为1) 的值写入内存;如果不相等(意味着i的值被其他线程修改过),我们就不把j的值写入内存,而是重新跳回步骤 1,继续这三个操作。
翻译成代码的话就是这样:
public static void increment() {
do{
int k = i;
int j = k + 1;
}while (compareAndSet(i, k, j))
}
cas是操作系统的一条硬件操作指令,是一种无锁机制,无需切换到内核态。
ABA问题:
比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。
原子类在内部使用 CAS 指令(基于硬件的支持)来实现同步。这些指令通常比锁更快。
原子变量类可以分为 4 组:
基本类型
- AtomicBoolean - 布尔类型原子类
- AtomicInteger - 整型原子类
- AtomicLong - 长整型原子类
引用类型
- AtomicReference - 引用类型原子类
- AtomicMarkableReference - 带有标记位的引用类型原子类
- AtomicStampedReference - 带有版本号的引用类型原子类,解决了ABA问题
数组类型
- AtomicIntegerArray - 整形数组原子类
- AtomicLongArray - 长整型数组原子类
- AtomicReferenceArray - 引用类型数组原子类
字段类型
- AtomicIntegerFieldUpdater - 整型字段的原子更新器。
- AtomicLongFieldUpdater - 长整型字段的原子更新器。
- AtomicReferenceFieldUpdater - 原子更新引用类型里的字段。
1、基本类型
// 获取当前值,然后自加,相当于i++
getAndIncrement()
// 获取当前值,然后自减,相当于i--
getAndDecrement()
// 自加1后并返回,相当于++i
incrementAndGet()
// 自减1后并返回,相当于--i
decrementAndGet()
// 获取当前值,并加上预期值
getAndAdd(int delta)
// 获取当前值,并设置新值
int getAndSet(int newValue)
// ...
2、引用类型
public class AtomicReference<V> implements java.io.Serializable {
public final V get() {
return value;
}
public final void set(V newValue) {
value = newValue;
}
public final boolean compareAndSet(V expectedValue, V newValue) {
return VALUE.compareAndSet(this, expectedValue, newValue);
}
// ...省略其他
}
可以看到AtomicReference是一个泛型类,内部设置及更新引用类型数据的方法。以compareAndSet方法为例来看如何使用。
public class Book {
public String name;
public int price;
public Book(String name, int price) {
this.name = name;
this.price = price;
}
}
AtomicReference<Book> atomicReference = new AtomicReference<>();
Book book1 = new Book("三国演义", 42);
atomicReference.set(book1);
Book book2 = new Book("水浒传", 40);
atomicReference.compareAndSet(book1, book2);
System.out.println("Book name is " + atomicReference.get().name + ",价格是" + atomicReference.get().price);
输出结果为:Book name is 水浒传,价格是40
上述代码首先将book1关联AtomicReference,接着又实例化了book2。调用compareAndSet方法传入book1和book2两个参数,通过CAS更新book。首先判断期望的是不是book1,如果是则更新为book2.否则继续自旋知道更新成功。
3、数组类型
public class AtomicIntegerArray implements java.io.Serializable {
// final类型的int数组
private final int[] array;
// 获取数组中第i个元素
public final int get(int i) {
return (int)AA.getVolatile(array, i);
}
// 设置数组中第i个元素
public final void set(int i, int newValue) {
AA.setVolatile(array, i, newValue);
}
// CAS更改第i个元素
public final boolean compareAndSet(int i, int expectedValue, int newValue) {
return AA.compareAndSet(array, i, expectedValue, newValue);
}
// 获取第i个元素,并加1
public final int getAndIncrement(int i) {
return (int)AA.getAndAdd(array, i, 1);
}
// 获取第i个元素并减1
public final int getAndDecrement(int i) {
return (int)AA.getAndAdd(array, i, -1);
}
// 对数组第i个元素加1后再获取
public final int incrementAndGet(int i) {
return (int)AA.getAndAdd(array, i, 1) + 1;
}
// 对数组第i个元素减1后再获取
public final int decrementAndGet(int i) {
return (int)AA.getAndAdd(array, i, -1) - 1;
}
// ... 省略
}
4、字段类型
如果要更新某个对象中的某个字段,可以使用更新对象字段的原子类。
需要注意的是这些类的使用需要满足以下条件才可。
- 被操作的字段不能是static类型;
- 被操纵的字段不能是final类型;
- 被操作的字段必须是volatile修饰的;
- 属性必须对于当前的Updater所在区域是可见的。
public class Book {
public String name;
public volatile int price;
public Book(String name, int price) {
this.name = name;
this.price = price;
}
}
AtomicIntegerFieldUpdater<Book> updater = AtomicIntegerFieldUpdater.newUpdater(Book.class, "price");
Book book = new Book("三国演义", 42);
updater.set(book, 50);
System.out.println( "更新后的价格是" + updater.get(book));
AQS,全名AbstractQueuedSynchronizer,是一个抽象类的队列式同步器,它的内部通过维护一个状态volatile int state(共享资源),一个FIFO线程等待队列来实现同步功能。
state用关键字volatile修饰,代表着该共享资源的状态一更改就能被所有线程可见,而AQS的加锁方式本质上就是多个线程在竞争state,当state为0时代表线程可以竞争锁,不为0时代表当前对象锁已经被占有,其他线程来加锁时则会失败,加锁失败的线程会被放入一个FIFO的等待队列中,这些线程会被UNSAFE.park()操作挂起,等待其他获取锁的线程释放锁才能够被唤醒。
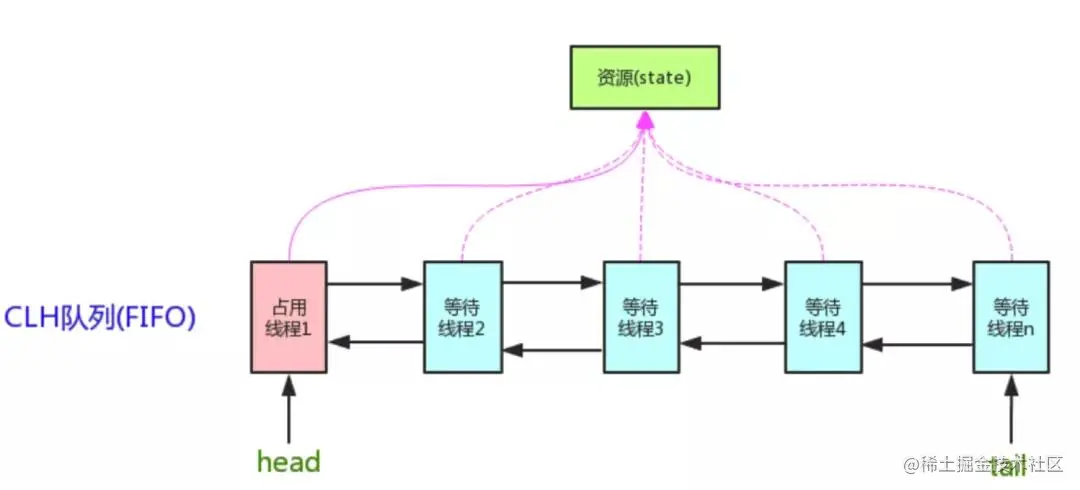
AQS支持两种资源分享的方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
自定义的同步器继承AQS后,只需要实现共享资源state的获取和释放方式即可,其他如线程队列的维护(如获取资源失败入队/唤醒出队等)等操作,AQS在顶层已经实现了。
AQS代码内部提供了一系列操作锁和线程队列的方法,主要操作锁的方法包含以下几个:
- compareAndSetState():利用CAS的操作来设置state的值
- tryAcquire(int):独占方式获取锁。成功则返回true,失败则返回false。
- tryRelease(int):独占方式释放锁。成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式释放锁。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式释放锁。如果释放后允许唤醒后续等待结点返回true,否则返回false。
static final class Node {
/** 表示共享模式下等待的Node */
static final Node SHARED = new Node();
/** 表示独占模式下等待的mode */
static final Node EXCLUSIVE = null;
/** 下面几个为waitStatus的具体值 */
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
/** 表示前面的结点 */
volatile Node prev;
/** 表示后面的结点 */
volatile Node next;
/**当前结点装载的线程,初始化时被创建,使用后会置空*/
volatile Thread thread;
/**链接到下一个节点的等待条件,用到Condition的时候会使用到*/
Node nextWaiter;
}
代码里面定义了一个表示当前Node结点等待状态的字段waitStatus,该字段的取值包含了CANCELLED(1)、SIGNAL(-1)、CONDITION(-2)、PROPAGATE(-3)、0,这五个值代表了不同的特定场景:
-
CANCELLED:表示当前结点已取消调度。当timeout或被中断(响应中断的情况下),会触发变更为此状态,进入该状态后的结点将不会再变化。
-
SIGNAL:表示后继结点在等待当前结点唤醒。后继结点入队时,会将前继结点的状态更新为SIGNAL(记住这个-1的值,因为后面我们讲的时候经常会提到)
-
CONDITION:表示结点等待在Condition上,当其他线程调用了Condition的signal()方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。(注:Condition是AQS的一个组件,后面会细说)
-
PROPAGATE:共享模式下,前继结点不仅会唤醒其后继结点,同时也可能会唤醒后继的后继结点。
-
0:新结点入队时的默认状态。
也就是说,当waitStatus为负值表示结点处于有效等待状态,为正值的时候表示结点已被取消。
加锁过程:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
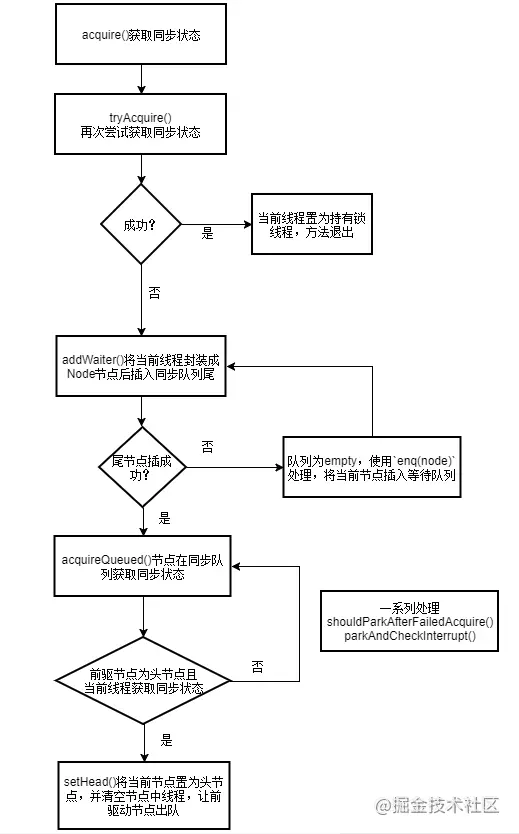
线程进来后直接利用CAS尝试抢占锁,如果抢占成功state值回被改为1,且设置对象独占锁线程为当前线程,否则就调用acquire(1)再次尝试获取锁。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
acquire包含了几个函数的调用
- tryAcquire:尝试直接获取锁,如果成功就直接返回;
- addWaiter:将该线程加入等待队列FIFO的尾部,并标记为独占模式;
- acquireQueued:线程阻塞在等待队列中获取锁,一直获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
- selfInterrupt:自我中断,就是既拿不到锁,又在等待时被中断了,线程就会进行自我中断selfInterrupt(),将中断补上。
tryAcquire
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
当线程B进来后,nonfairTryAcquire方法首先会获取state的值,如果为0,则正常获取该锁,不为0的话判断是否是当前线程占用了,是的话就累加state的值,这里的累加也是为了配合释放锁时候的次数,从而实现可重入锁的效果。 当然,因为之前锁已经被线程A占领了,所以这时候tryAcquire会返回false,继续下面的流程。
addWaiter
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
这段代码首先会创建一个和当前线程绑定的Node节点,Node为双向链表。此时等待队列中的tail指针为空,直接调用enq(node)方法将当前线程加入等待队列尾部,然后返回当前结点的前驱结点。
acquireQueued
acquireQueued用于已在队列中的线程以独占且不间断模式获取state状态,直到获取锁后返回。
流程:
- 结点node进入队列尾部后,检查状态;
- 调用park()进入waiting状态,等待unpark()或interrupt()唤醒;
- 被唤醒后,是否获取到锁。如果获取到,head指向当前结点,并返回从入队到获取锁的整个过程中是否被中断过;如果没获取到,继续流程1
final boolean acquireQueued(final Node node, int arg) {
//是否已获取锁的标志,默认为true 即为尚未
boolean failed = true;
try {
//等待中是否被中断过的标记
boolean interrupted = false;
for (;;) {
//获取前节点
final Node p = node.predecessor();
//如果当前节点已经成为头结点,尝试获取锁(tryAcquire)成功,然后返回
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
//shouldParkAfterFailedAcquire根据对当前节点的前一个节点的状态进行判断,对当前节点做出不同的操作
//parkAndCheckInterrupt让线程进入等待状态,并检查当前线程是否被可以被中断
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
//将当前节点设置为取消状态;取消状态设置为1
if (failed)
cancelAcquire(node);
}
}
解锁过程:
release方法是独占exclusive模式下线程释放共享资源的锁。它会调用tryRelease()释放同步资源,如果全部释放了同步状态为空闲(即state=0),当同步状态为空闲时,它会唤醒等待队列里的其他线程来获取资源。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
共享式与独占式的最主要区别在于同一时刻独占式只能有一个线程获取同步状态,而共享式在同一时刻可以有多个线程获取同步状态。例如读操作可以有多个线程同时进行,而写操作同一时刻只能有一个线程进行写操作,其他操作都会被阻塞。
如Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock
(1)使用
public class Counter {
private final Lock lock = new ReentrantLock();
private int count;
public void add(int n) {
lock.lock();
try {
count += n;
} finally {
lock.unlock();
}
}
}
因为synchronized是Java语言层面提供的语法,所以我们不需要考虑异常,而ReentrantLock是Java代码实现的锁,我们就必须先获取锁,然后在finally中正确释放锁。
顾名思义,ReentrantLock是可重入锁,它和synchronized一样,一个线程可以多次获取同一个锁。
和synchronized不同的是,ReentrantLock可以尝试获取锁:
if (lock.tryLock(1, TimeUnit.SECONDS)) {
try {
...
} finally {
lock.unlock();
}
}
(2)比较
synchronized 是 Java 语言层面提供的一个关键字,锁和获取和释放都不需要显式调用,在异常时也会自动释放锁。
与之相比,ReentrantLock 是 Java 语法层面提供的API,是一种手动锁,需要手动获取锁lock()和释放锁unlock(),并要手动处理异常。一方面使用更加灵活,另一方面也需要特别注意,一定要记得释放锁,不然就会造成死锁。
ReentrantLock因为要手动释放锁,为避免异常时无法释放锁,需要配合try/finally语句块来完成,在finally中释放锁,保证异常时锁也能够释放成功。
轻量级锁
synchronized是重量级锁。重量级锁需要将线程从内核态和用户态来回切换。如:A线程切换到B线程,A线程需要保存当前现场,B线程切换也需要保存现场。这样做的缺点是耗费系统资源。而ReentrantLock是轻量级锁。
可重入
ReentrantLock,意为再重入锁,顾名思义,它是可重入锁,和synchronized一样,一个线程可以多次获取同一个锁。 对于ReentrantLock,在调用lock()方法时,已经获取到锁的线程,能够再次调用lock()方法获取锁而不被阻塞。ReentrantLock内部有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放。
锁类型:公平锁与非公平锁
公平锁:多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁;
非公平锁:不保证先到先得,在锁被释放时,任何一个等待锁的线程都有机会获得锁,是一种抢占机制。这个方式可能造成某些线程一直拿不到锁,结果也就是不公平的了。它的效率和吞吐率通常比公平锁更好。 synchronized锁是非公平锁。
非公平锁性能高于公平锁性能
ReentrantLock的构造函数提供了两种锁:公平锁和非公平锁,默认是非公平锁,
/**
* 默认构造方法,非公平锁
*/
public ReentrantLock() {
sync = new NonfairSync();
}
/**
* true公平锁,false非公平锁
* @param fair
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
// 创建一个 ReentrantLock ,默认是“非公平锁”。
ReentrantLock()
// 创建策略是fair的 ReentrantLock。fair为true表示是公平锁,fair为false表示是非公平锁。
ReentrantLock(boolean fair)
(1)使用
使用ReentrantLock比直接使用synchronized更安全,可以替代synchronized进行线程同步。
但是,synchronized可以配合wait和notify实现线程在条件不满足时等待,条件满足时唤醒,用ReentrantLock我们怎么编写wait和notify的功能呢?
答案是使用Condition对象来实现wait和notify的功能。
//响应线程中断的条件等待
void await() throws InterruptedException;
//不响应线程中断的条件等待
void awaitUninterruptibly();
//设置相对时间的条件等待(不进行自旋)
long awaitNanos(long nanosTimeout) throws InterruptedException;
//设置相对时间的条件等待(进行自旋)
boolean await(long time, TimeUnit unit) throws InterruptedException;
//设置绝对时间的条件等待
boolean awaitUntil(Date deadline) throws InterruptedException;
//唤醒条件队列中的头结点
void signal();
//唤醒条件队列的所有结点
void signalAll();
class TaskQueue {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private Queue<String> queue = new LinkedList<>();
public void addTask(String s) {
lock.lock();
try {
queue.add(s);
condition.signalAll();
} finally {
lock.unlock();
}
}
public String getTask() {
lock.lock();
try {
while (queue.isEmpty()) {
condition.await();
}
return queue.remove();
} finally {
lock.unlock();
}
}
}
可见,使用Condition时,引用的Condition对象必须从Lock实例的newCondition()返回,这样才能获得一个绑定了Lock实例的Condition实例。
Condition提供的await()、signal()、signalAll()原理和synchronized锁对象的wait()、notify()、notifyAll()是一致的
(2)原理
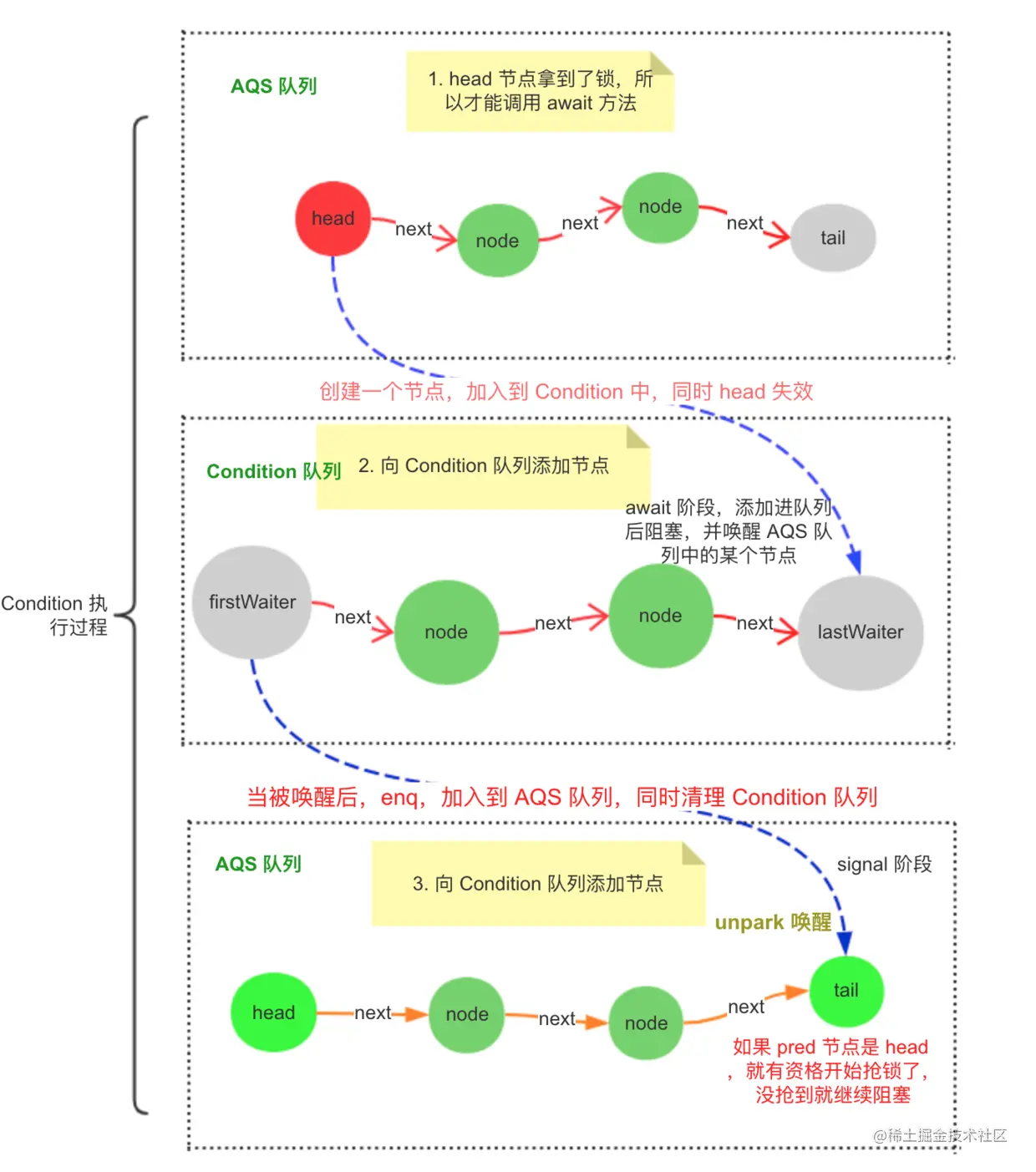
-
首先,线程如果想执行 await 方法,必须拿到锁,在 AQS 里面,抢到锁的一般都是 head,然后 head 失效,从队列中删除。
-
在当前线程(也就是 AQS 的 head)拿到锁后,调用了 await 方法,第一步创建一个 Node 节点,放到 Condition 自己的队列尾部,并唤醒 AQS 队列中的某个(head)节点,然后阻塞自己,等待被 signal 唤醒。
-
当有其他线程调用了 signal 方法,就会唤醒 Condition 队列中的 first 节点,然后将这个节点放进 AQS 队列的尾部。
-
阻塞在 await 方法的线程苏醒后,他已经从 Condition 队列总转移到 AQS 队列中了,这个时候,他就是一个正常的 AQS 节点,就会尝试抢锁。并清除 Condition 队列中无效的节点。
public class Counter {
private final ReadWriteLock rwlock = new ReentrantReadWriteLock();
private final Lock rlock = rwlock.readLock();
private final Lock wlock = rwlock.writeLock();
private int[] counts = new int[10];
public void inc(int index) {
wlock.lock(); // 加写锁
try {
counts[index] += 1;
} finally {
wlock.unlock(); // 释放写锁
}
}
public int[] get() {
rlock.lock(); // 加读锁
try {
return Arrays.copyOf(counts, counts.length);
} finally {
rlock.unlock(); // 释放读锁
}
}
}
(1)使用
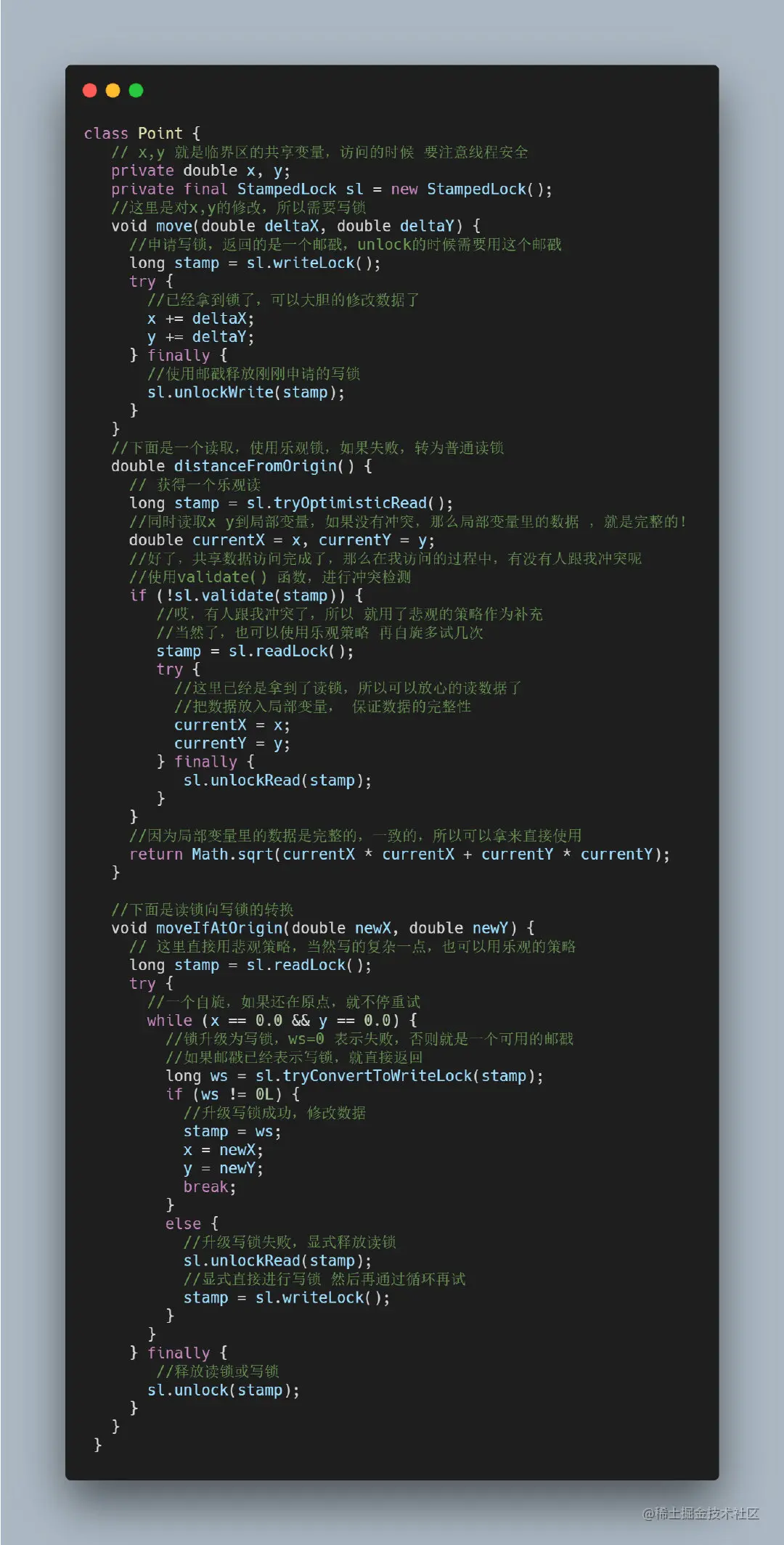
(2)原理
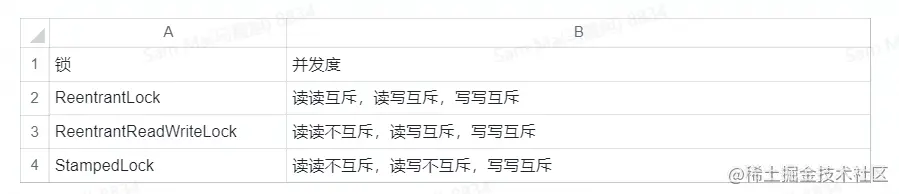
从ReentrantLock到ReentrantReadWriteLock,再到StampedLock,读操作并发度依次提高。
ReentrantReadWriteLock采用“悲观读”策略,当第一个读线程抢到共享锁,第二个、第三个读线程还可以抢到共享锁,使得写线程一直无法获取互斥写锁,会导致写线程“饿死”。
读写锁的公平/非公平实现中,尽量避免这种情形,但还有可能发生。
StampedLock通过读写不互斥进一步提高读的并发量。
(3)流程
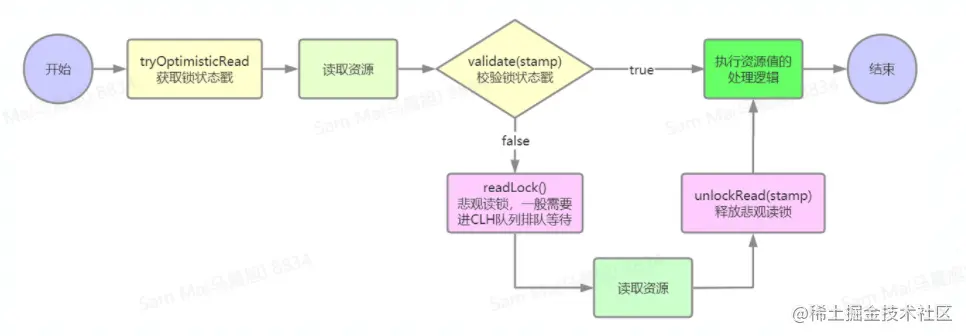
(4)原理
是基于CAS实现的,是悲观写,乐观读,读的时候不加锁
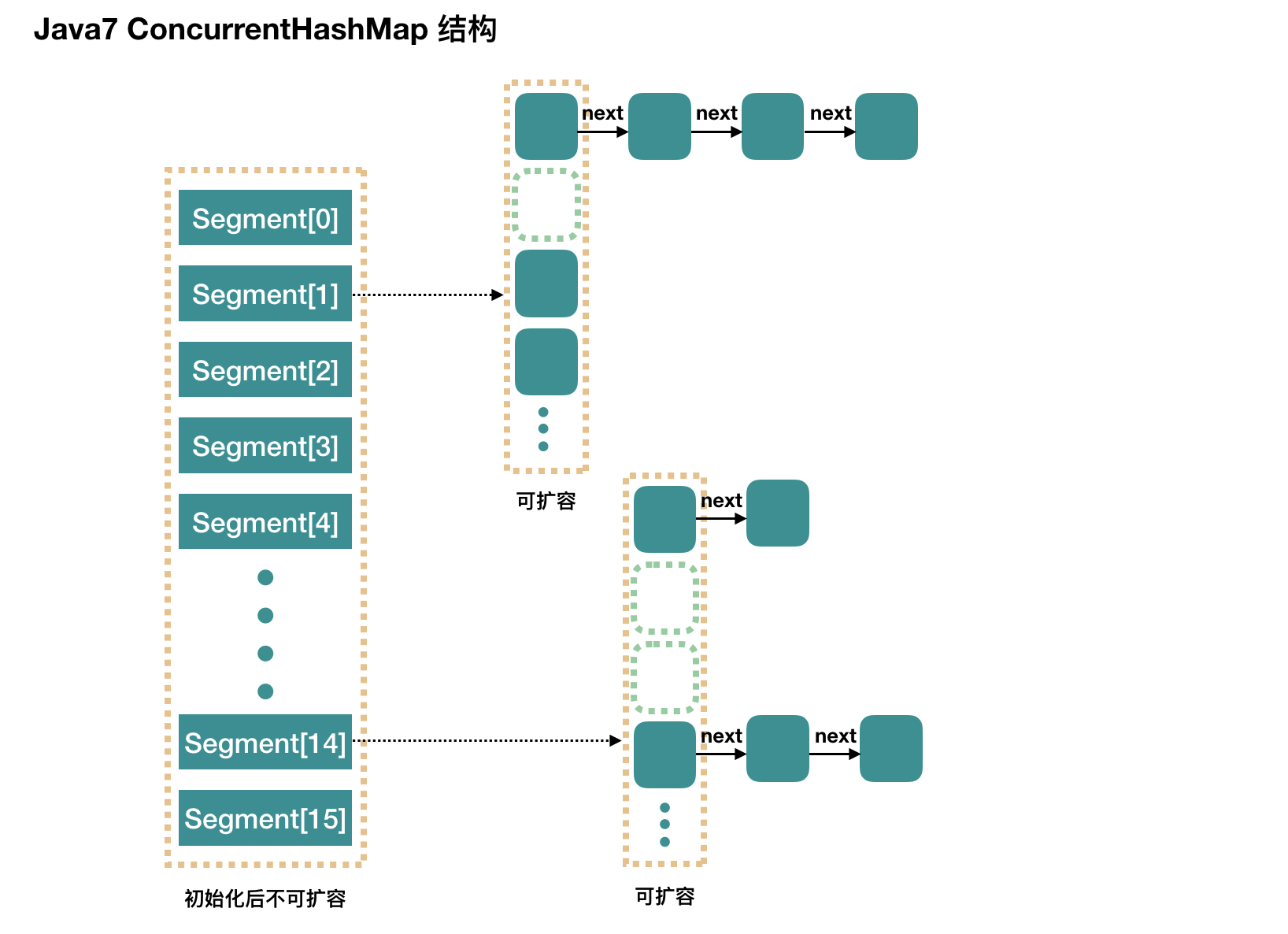
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,即每个分段则类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
CopyOnWriteArrayList是ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的拷贝来实现的。
CopyOnWriteArrayList 有几个缺点:
- 由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
- 不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
ConcurerntLinkedQueue一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue是一个恰当的选择。此队列不允许使用null元素。
ConcurerntLinkedQueue基于使用CAS(Compare And Swap)进行操作,是一种无锁队列。
lockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。
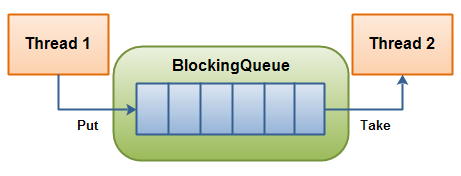
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
| 特 性 | LinkedBlockingQueue | ConcurrentLinkedQueue |
|---|---|---|
| 阻塞性 | 阻塞队列,并实现blocking queue接口 | 非阻塞队列,不实现blocking queue接口 |
| 队列大小 | 可选的有界队列,这意味着可以在创建期间定义队列大小 | 无边界队列,并且没有在创建期间指定队列大小的规定 |
| 锁特性 | 基于锁的队列 | 无锁队列 |
| 算法 | 锁的实现基于 “双锁队列(two lock queue)” 算法 | 依赖于Michael&Scott算法来实现无阻塞、无锁队列 |
| 实现 | 在 双锁队列 算法机制中,LinkedBlockingQueue使用两种不同的锁,putLock和takeLock。put/take操作使用第一个锁类型,take/poll操作使用另一个锁类型 | 使用CAS(Compare And Swap)进行操作 |
| 阻塞行为 | 当队列为空时,它会阻塞访问线程 | 当队列为空时返回 null,它不会阻塞访问线程 |
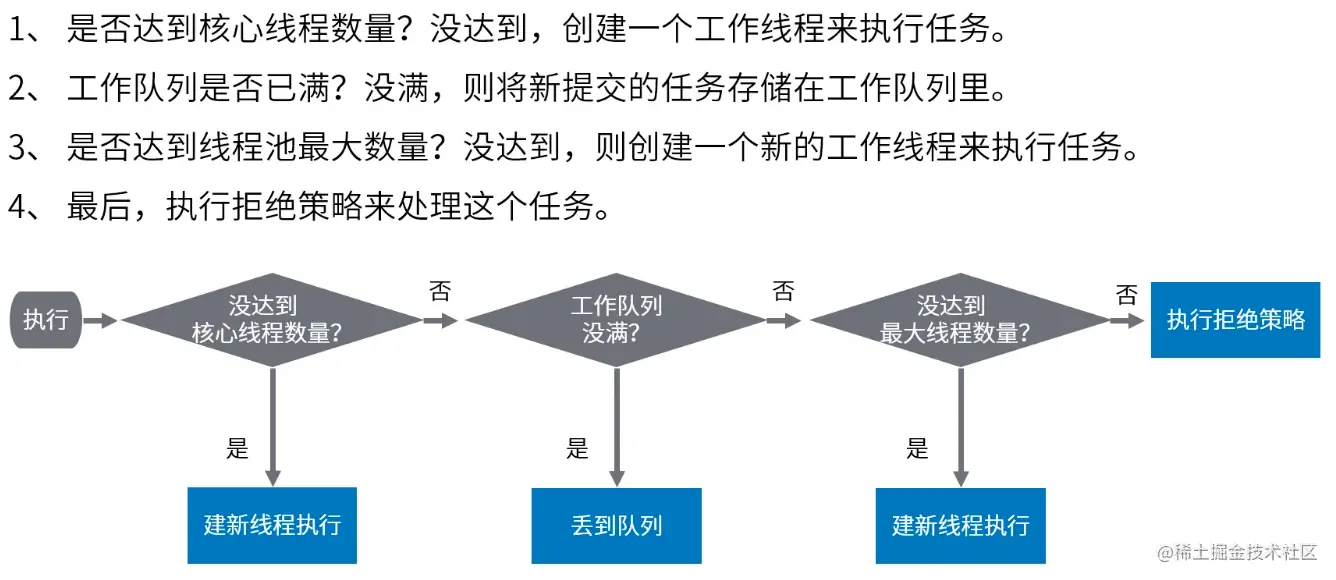
- 线程池管理器:用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务;
- 工作线程:线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口:每个任务必须实现的借口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列:用于存放没有处理的任务。提供一种缓冲机制。
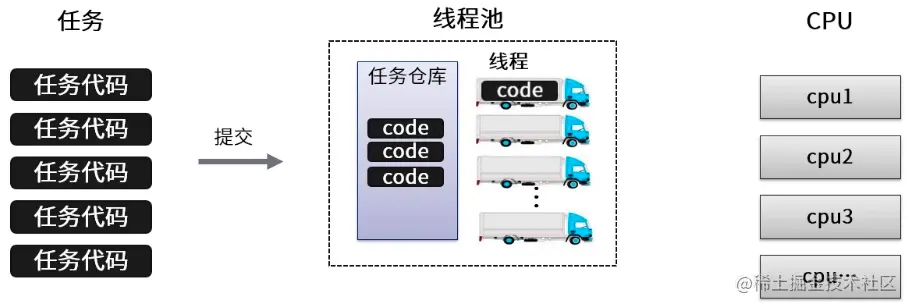
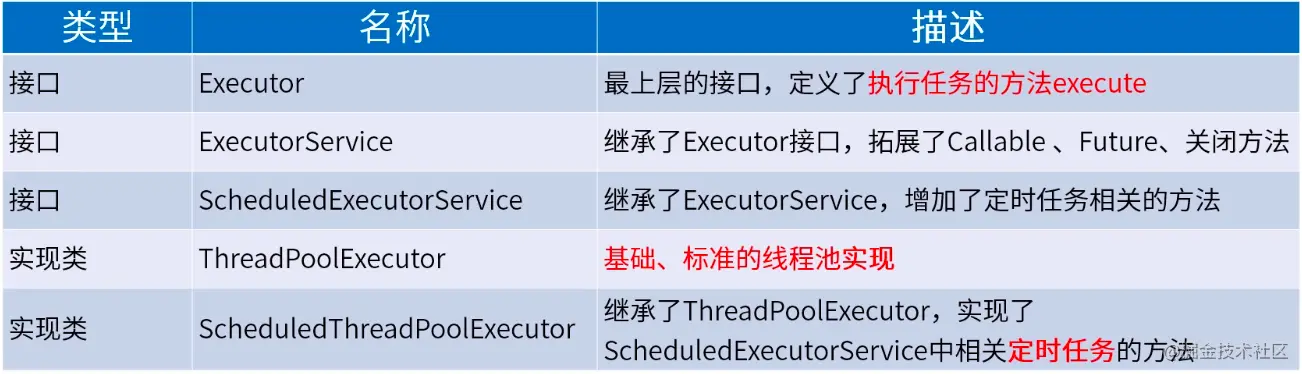
ExecutorService只是接口,Java标准库提供的几个常用实现类有:
- FixedThreadPool:线程数固定的线程池;
- CachedThreadPool:线程数根据任务动态调整的线程池;
- SingleThreadExecutor:仅单线程执行的线程池。
public class Main {
public static void main(String[] args) {
// 创建一个固定大小的线程池:
ExecutorService es = Executors.newFixedThreadPool(4);
for (int i = 0; i < 6; i++) {
es.submit(new Task("" + i));
}
// 关闭线程池:
es.shutdown();
}
}
class Task implements Runnable {
private final String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("start task " + name);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println("end task " + name);
}
}
// 创建单一线程的线程池
public static ExecutorService newSingleThreadExecutor();
// 创建固定数量的线程池
public static ExecutorService newFixedThreadPool(int nThreads);
// 创建带缓存的线程池
public static ExecutorService newCachedThreadPool();
// 创建定时调度的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize);
// 创建流式(fork-join)线程池
public static ExecutorService newWorkStealingPool();
往线程池中提交任务,主要有两种方法,execute()和submit()。
execute()用于提交不需要返回结果的任务
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.execute(() -> System.out.println("hello"));
}
submit()用于提交一个需要返回果的任务。该方法返回一个Future对象,通过调用这个对象的get()方法,我们就能获得返回结果。
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(2);
Future<Long> future = executor.submit(() -> {
System.out.println("task is executed");
return System.currentTimeMillis();
});
System.out.println("task execute time is: " + future.get());
}
在线程池使用完成之后,我们需要对线程池中的资源进行释放操作,这就涉及到关闭功能。我们可以调用线程池对象的shutdown()和shutdownNow()方法来关闭线程池。
这两个方法都是关闭操作,又有什么不同呢?
- shutdown()会将线程池状态置为SHUTDOWN,不再接受新的任务,同时会等待线程池中已有的任务执行完成再结束。
- shutdownNow()会将线程池状态置为SHUTDOWN,对所有线程执行interrupt()操作,清空队列,并将队列中的任务返回回来。
- 如果是CPU密集型应用,则线程池大小设置为N+1 (N为CPU总核数)
- 如果是IO密集型应用,则线程池大小设置为2N+1 (N为CPU总核数)
- 线程等待时间(IO)所占比例越高,需要越多线程。
- 线程CPU时间所占比例越高,需要越少线程。
我们可以通过Runtime.getRuntime().availableProcessors()来获取CPU的个数。
CountDownLatch 是多线程控制的一种工具,它被称为 门阀、 计数器或者 闭锁。这个工具经常用来用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。
CountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。它相当于是一个计数器,这个计数器的初始值就是线程的数量,每当一个任务完成后,计数器的值就会减一,当计数器的值为 0 时,表示所有的线程都已经任务了,然后在 CountDownLatch 上等待的线程就可以恢复执行接下来的任务。
-
CountDownLatch(int count): 类中唯一的构造器,count为倒数的次数;
-
await(): 调用该方法的线程会被挂起,直到count为0时才会被唤醒;
-
countDown(): 将count执行减一操作,当count为0时,等待中的线程会被唤醒;
-
getCount(): 获取latch数量。
(1)一等多
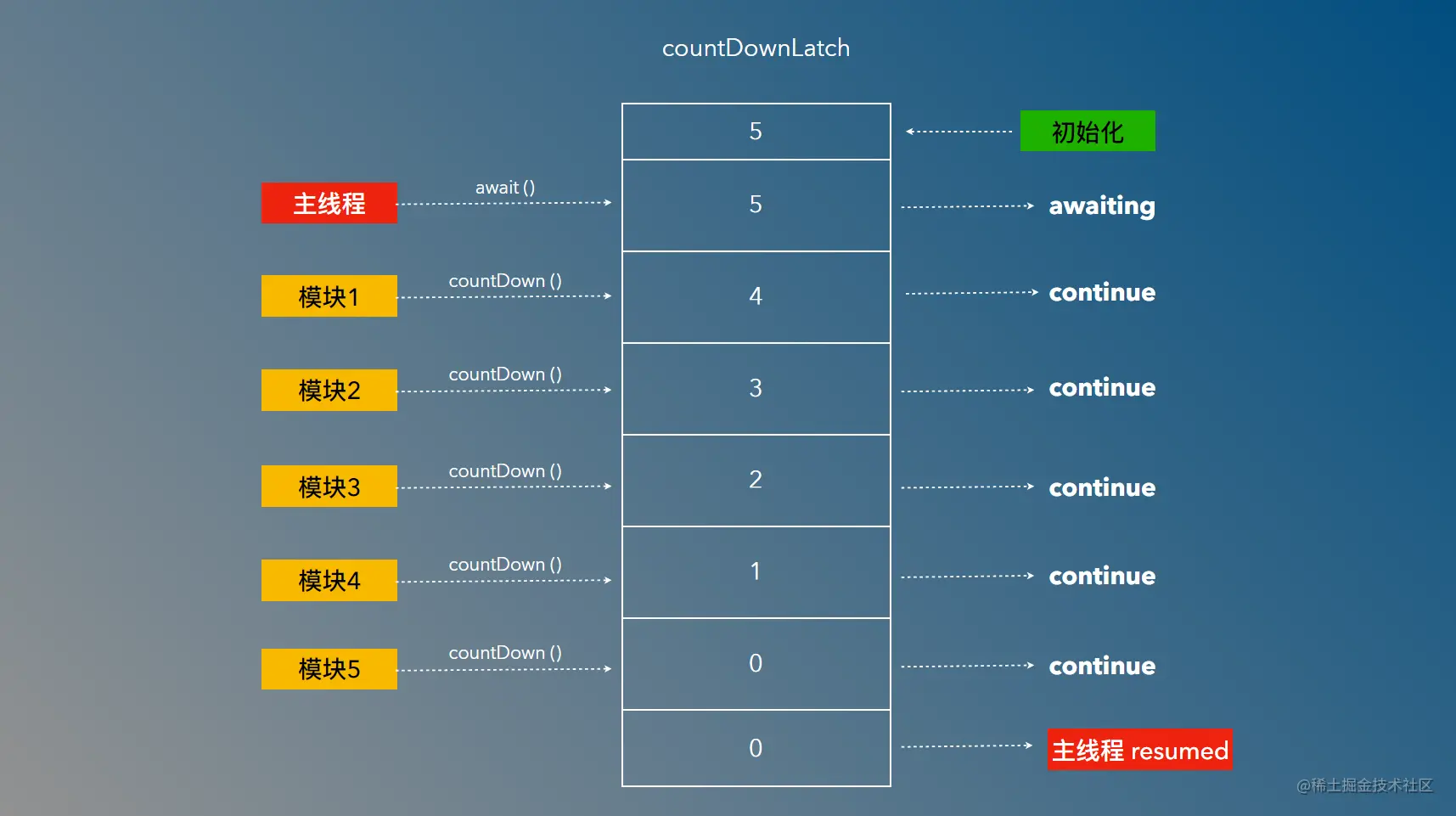
我们开发软件的目的是上线供用户使用,那再上线前肯定需要对系统进行全面测试,而很多模块间并没有依赖关系,因此可以同时进行测试,等待所以模块测试完毕,才能进行正式上线。 本例中假设有五个模块需要测试,并且模块测试可以同步进行,当每个模块测试完毕后会调用countDown方法,执行减一操作,等到count为0时,调用了await()方法的主线程从挂起状态被激活,继续执行。
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
ExecutorService service = Executors.newFixedThreadPool(5);
//创建5个线程,分别执行不通模块测试
for (int i = 1; i <= 5; i++) {
final int num = i;
Runnable runnable = () -> {
try {
//模拟测试耗时
Thread.sleep((long) (Math.random()*5000));
System.out.println("模块:"+ num +"测试完毕");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
//测试完毕后执行减一操作
latch.countDown();
}
};
service.submit(runnable);
}
System.out.println("等待模块检测...");
//主线程等待,直到count为0
latch.await();
System.out.println("所有模块测试完毕,开始上线");
}
等待模块检测...
模块:2测试完毕
模块:5测试完毕
模块:4测试完毕
模块:3测试完毕
模块:1测试完毕
所有模块测试完毕,开始上线
(2)多等一
这里使用运动会赛跑的栗子:在运动会上,所有运动员会先进行准备动作,只有等到裁判员发出信号,所有人才能开始比赛。 与之前的例子主要区别在于:CountDownLatch初始变量count为1,然后所有线程调用await方法进行等待,直到主线程调用countDown方法将count值减为1,此时所有线程同时被唤醒,开始执行自身逻辑。
public static void main(String[] args) throws InterruptedException {
//重点:这里初始化为1
CountDownLatch begin = new CountDownLatch(1);
ExecutorService service = Executors.newFixedThreadPool(5);
//创建5个线程
for (int i = 1; i <= 5; i++) {
final int num = i;
Runnable runnable = () -> {
try {
System.out.println("运动员:"+ num +"等待起跑指令");
//所有运动员等待指令
begin.await();
System.out.println("运动员:"+ num +"开始跑步");
} catch (InterruptedException e) {
e.printStackTrace();
}
};
service.submit(runnable);
}
Thread.sleep(1000);
//裁判员发出起步指令
begin.countDown();
System.out.println("发令完毕");
}
运动员:1等待起跑指令
运动员:3等待起跑指令
运动员:4等待起跑指令
运动员:2等待起跑指令
运动员:5等待起跑指令
发令完毕
运动员:3开始跑步
运动员:4开始跑步
运动员:1开始跑步
运动员:5开始跑步
运动员:2开始跑步
(1)比较
- CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;
- CyclicBarrier:多个线程互相等待,直到到达同一个同步点,再继续一起执行。
(2)使用
1、会议需要三个人
CyclicBarrier cyclicBarrier = new CyclicBarrier(3, new Runnable() {
@Override
public void run()
2、这是三个人都到齐之后会执行的代码
System.out.println("三个人都已到达会议室")
}
});
3、定义三个线程,相当于三个参会的人
for (int i = 0; i < 3; i++) {
final int finalI = i;
new Thread(new Runnable() {
@Override
public void run() {
try {
4、模拟每人到会议室所需时间
Thread.sleep((long) (Math.random()*5000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第"+Thread.currentThread().getName()+"个人到达会议室");
try {
5、等待其他人到会议室
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"开始开会");
}
}, String.valueOf(finalI)).start();
}
(1)使用
// 调用该方法后线程会从许可集中尝试获取一个许可
public void acquire()
// 线程调用该方法时会释放已获取的许可
public void release()
// Semaphore构造方法:permits→许可集数量
Semaphore(int permits)
// Semaphore构造方法:permits→许可集数量,fair→公平与非公平
Semaphore(int permits, boolean fair)
// 从信号量中获取许可,该方法不响应中断
void acquireUninterruptibly()
// 返回当前信号量中未被获取的许可数
int availablePermits()
// 获取并返回当前信号量中立即未被获取的所有许可
int drainPermits()
// 返回等待获取许可的所有线程Collection集合
protected Collection<Thread> getQueuedThreads();
// 返回等待获取许可的线程估计数量
int getQueueLength()
// 查询是否有线程正在等待获取当前信号量中的许可
boolean hasQueuedThreads()
// 返回当前信号量的公平类型,如为公平锁返回true,非公平锁为false
boolean isFair()
// 获取当前信号量中一个许可,当没有许可可用时直接返回false不阻塞线程
boolean tryAcquire()
// 在给定时间内获取当前信号量中一个许可,超时还未获取成功则返回false
boolean tryAcquire(long timeout, TimeUnit unit)
(2)原理
Semaphore的实现是基于AQS的共享锁,分为公平和非公平两种模式。
1、简介
多线程访问同一个共享变量的时候容易出现并发问题,特别是多个线程对一个变量进行写入的时候,为了保证线程安全,一般使用者在访问共享变量的时候需要进行额外的同步措施才能保证线程安全性。ThreadLocal是除了加锁这种同步方式之外的一种保证一种规避多线程访问出现线程不安全的方法,当我们在创建一个变量后,如果每个线程对其进行访问的时候访问的都是线程自己的变量这样就不会存在线程不安全问题。
ThreadLocal是JDK包提供的,它提供线程本地变量,如果创建一乐ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个副本,在实际多线程操作的时候,操作的是自己本地内存中的变量,从而规避了线程安全问题,如下图所示
2、使用
public class ThreadLocaTest {
private static ThreadLocal<String> local = new ThreadLocal<String>();
static void print(String str) {
//打印当前线程中本地内存中变量的值
System.out.println(str + " :" + local.get());
//清除内存中的本地变量
localVar.remove();
}
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
public void run() {
ThreadLocaTest.local.set("xdclass_A");
print("A");
//打印本地变量
System.out.println("清除后:" + local.get());
}
},"A").start();
Thread.sleep(1000);
new Thread(new Runnable() {
public void run() {
ThreadLocaTest.local.set("xdclass_B");
print("B");
System.out.println("清除后 " + localVar.get());
}
},"B").start();
}
}
public static void main(String[] args) {
// 用匿名内部类的方式来创建线程
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("公众号:Java3y---关注我!");
}
});
// 使用Lambda来创建线程
new Thread(() -> System.out.println("公众号:Java3y---关注我!"));
}
- Lambda返回的是接口的实例对象
- 有没有参数、参数有多少个、需不需要有返回值、返回值的类型是什么---->选择自己合适的函数式接口
max
一般用于求数字集合中的最大值,或者按实体中数字类型的属性比较,拥有最大值的那个实体。它接收一个 Comparator,上面也举到这个例子了,它是一个函数式接口类型,专门用作定义两个对象之间的比较,例如下面这个方法使用了 Integer::compareTo这个方法引用。
private static void max(){
Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Integer max = integerStream.max(Integer::compareTo).get();
System.out.println(max);
}
当然,我们也可以自己定制一个 Comparator
private static void max(){
Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Comparator<Integer> comparator = (x, y) -> (x.intValue() < y.intValue()) ? -1 : ((x.equals(y)) ? 0 : 1);
Integer max = integerStream.max(comparator).get();
System.out.println(max);
}
count
返回元素个数。
Stream<String> a = Stream.of("a", "b", "c");
long x = a.count();
peek
建立一个通道,在这个通道中对 Stream 的每个元素执行对应的操作,对应 Consumer的函数式接口,这是一个消费者函数式接口,顾名思义,它是用来消费 Stream 元素的,比如下面这个方法,把每个元素转换成对应的大写字母并输出。
private static void peek() {
Stream<String> a = Stream.of("a", "b", "c");
List<String> list = a.peek(e->System.out.println(e.toUpperCase())).collect(Collectors.toList());
}
forEach
和 peek 方法类似,都接收一个消费者函数式接口,可以对每个元素进行对应的操作,但是和 peek 不同的是,forEach 执行之后,这个 Stream 就真的被消费掉了,之后这个 Stream 流就没有了,不可以再对它进行后续操作了,而 peek操作完之后,还是一个可操作的 Stream 对象。
private static void forEach() {
Stream<String> a = Stream.of("a", "b", "c");
a.forEach(e->System.out.println(e.toUpperCase()));
}
limit
获取前 n 条数据
private static void limit() {
Stream<String> a = Stream.of("a", "b", "c");
a.limit(2).forEach(e->System.out.println(e));
}
skip
跳过前 n 条数据
private static void skip() {
Stream<String> a = Stream.of("a", "b", "c");
a.skip(2).forEach(e->System.out.println(e));
}
distinct
元素去重
private static void distinct() {
Stream<String> a = Stream.of("a", "b", "c","b");
a.distinct().forEach(e->System.out.println(e));
}
sorted
有两个重载,一个无参数,另外一个有个 Comparator类型的参数。
无参类型的按照自然顺序进行排序,只适合比较单纯的元素,比如数字、字母等。
private static void sorted() {
Stream<String> a = Stream.of("a", "c", "b");
a.sorted().forEach(e->System.out.println(e));
}
有参数的需要自定义排序规则,例如下面这个方法,按照第二个字母的大小顺序排序,最后输出的结果是 a1、b3、c6。
private static void sortedWithComparator() {
Stream<String> a = Stream.of("a1", "c6", "b3");
a.sorted((x,y)->Integer.parseInt(x.substring(1))>Integer.parseInt(y.substring(1))?1:-1).forEach(e->System.out.println(e));
}
filter
用于条件筛选过滤,筛选出符合条件的数据。例如下面这个方法,筛选出性别为 0,年龄大于 50 的记录。
private static void filter(){
List<User> users = getUserData();
Stream<User> stream = users.stream();
stream.filter(user -> user.getGender().equals(0) && user.getAge()>50).forEach(e->System.out.println(e));
/**
*等同于下面这种形式 匿名内部类
*/
// stream.filter(new Predicate<User>() {
// @Override
// public boolean test(User user) {
// return user.getGender().equals(0) && user.getAge()>50;
// }
// }).forEach(e->System.out.println(e));
}
map
用于改变当前元素的类型,例如将 Integer 转为 String类型,将 DAO 实体类型,转换为 DTO 实例类型。
private static void map(){
List<User> users = getUserData();
Stream<User> stream = users.stream();
List<UserDto> userDtos = stream.map(user -> dao2Dto(user)).collect(Collectors.toList());
}
private static UserDto dao2Dto(User user){
UserDto dto = new UserDto();
BeanUtils.copyProperties(user, dto);
//其他额外处理
return dto;
}
Reduce
它的作用是每次计算的时候都用到上一次的计算结果
List costBeforeTax = Arrays.asList(100, 200, 300, 400, 500);
double bill = costBeforeTax.stream().map((cost) -> cost + .12*cost).reduce((sum, cost) -> sum + cost).get();
System.out.println("Total : " + bill);
collection
在进行了一系列操作之后,我们最终的结果大多数时候并不是为了获取 Stream 类型的数据,而是要把结果变为 List、Map 这样的常用数据结构,而 collection就是为了实现这个目的。
private static void collect(){
Stream<Integer> integerStream = Stream.of(1,2,5,7,8,12,33);
List<Integer> list = integerStream.filter(s -> s.intValue()>7).collect(Collectors.toList());
}
Collectors为我们提供了很多拿来即用的收集器。比如我们经常用到Collectors.toList()、Collectors.toSet()、Collectors.toMap()。
public class OptionalDemo {
private static final String DEFAULT_NAME = "javalover";
public static void main(String[] args) {
// 传入null,以身试法
getName(null);
}
// 取出c.name
public static void getName(C c){
// 旧代码 Java8之前
String name = (c!=null ? c.getName() : DEFAULT_NAME);
System.out.println("old: "+name);
// 新代码 Java8之后(下面的三个操作方法后面会介绍,这里简单了解下)
String nameNew = Optional
// 工厂方法,创建Optional<C>对象,如果c为null,则创建空的Optional<C>对象
.ofNullable(c)
// 提取name,这里要注意,即使c==null,这里也不会抛出NPE,而是返回空的Optional<String>,所以在处理数据时,我们不需要担心空指针异常
.map(c1->c1.getName())
// 获取optional的属性值,如果为null,则返回给定的实参DEFAULT_NAME
.orElse(DEFAULT_NAME);
System.out.println("new: "+nameNew);
}
}
class C{
private String name;
public C(String name) {
this.name = name;
}
// 省略getter/setter
}
1、序列化步骤:
- 步骤一:创建一个ObjectOutputStream输出流;
- 步骤二:调用ObjectOutputStream对象的writeObject输出可序列化对象。
2、反序列化步骤:
- 步骤一:创建一个ObjectInputStream输入流;
- 步骤二:调用ObjectInputStream对象的readObject()得到序列化的对象。
3、serialVersionUID号:
- serialVersionUID序列化ID,可以看成是序列化和反序列化过程中的“暗号”,在反序列化时,JVM会把字节流中的序列号ID和被序列化类中的序列号ID做比对,只有两者一致,才能重新反序列化,否则就会报异常来终止反序列化的过程。
- 如果在定义一个可序列化的类时,没有人为显式地给它定义一个serialVersionUID的话,则Java运行时环境会根据该类的各方面信息自动地为它生成一个默认的serialVersionUID,一旦像上面一样更改了类的结构或者信息,则类的serialVersionUID也会跟着变化!
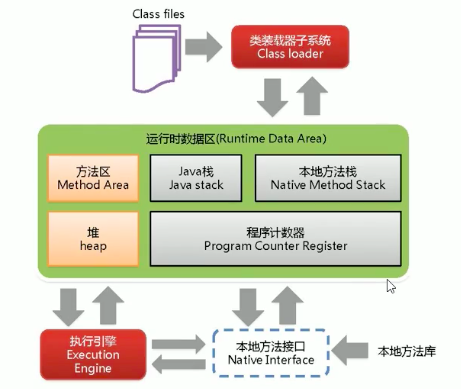
1、类装载子系统
2、运行时数据区
3、执行引擎
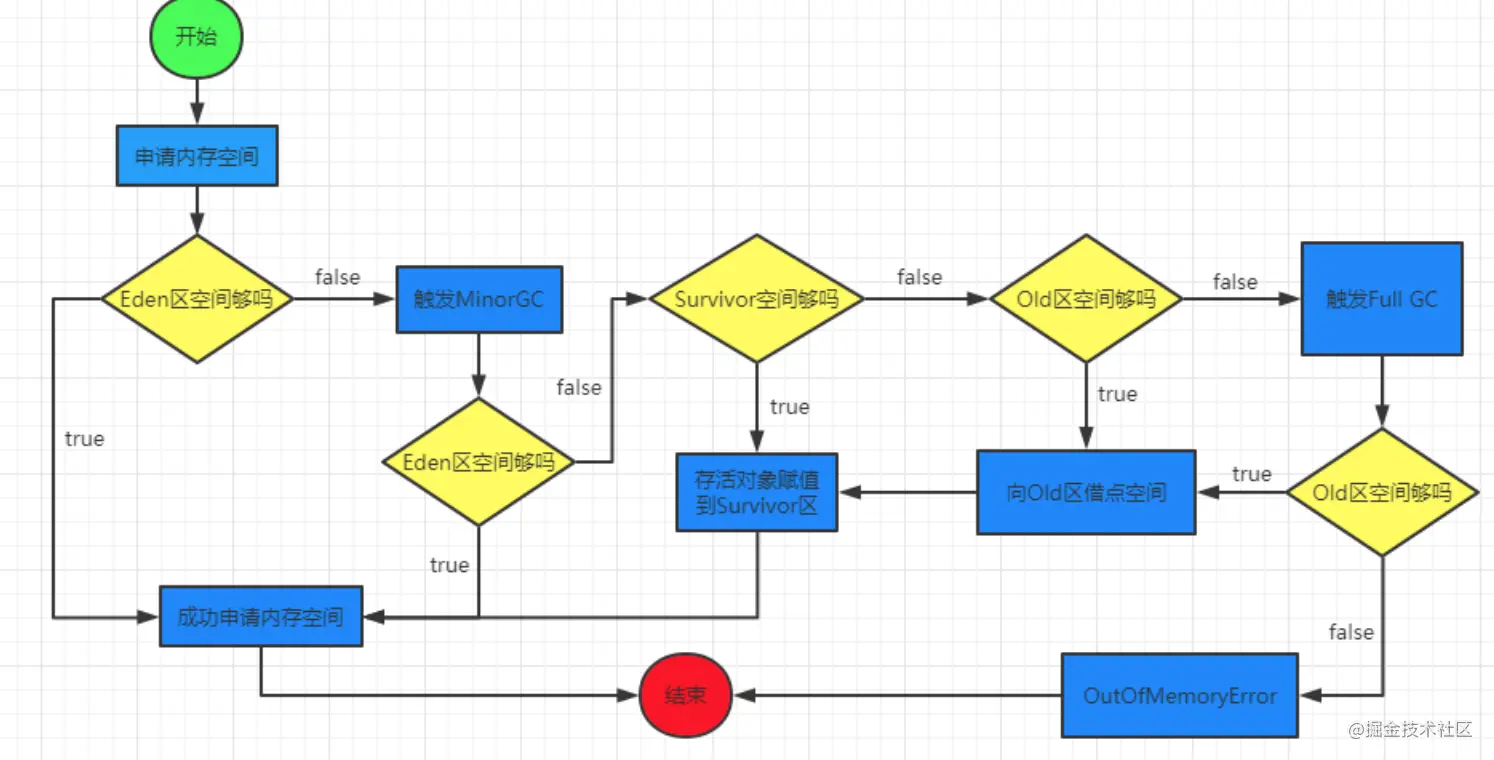
1、类的加载
首先将class文件读入内存,将其放到运行时数据区中的方法区,然后在堆中创建一个class对象
2、类加载过程
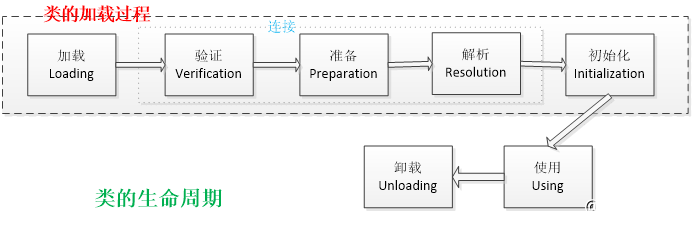
3、类加载器
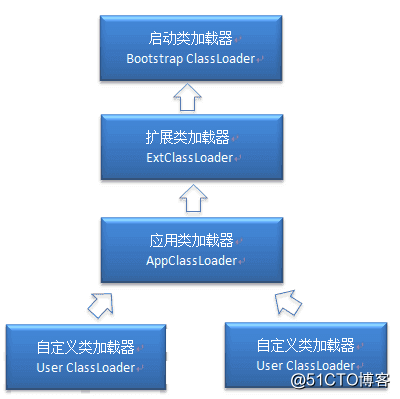
4、双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
- 当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。
- 当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给BootStrapClassLoader```去完成。
- 如果BootStrapClassLoader加载失败(例如在$JAVA_HOME/jre/lib里未查找到该class),会使用ExtClassLoader来尝试加载;
- 若ExtClassLoader也加载失败,则会使用AppClassLoader来加载,如果AppClassLoader也加载失败,则会报出异常ClassNotFoundException。
1、整体结构
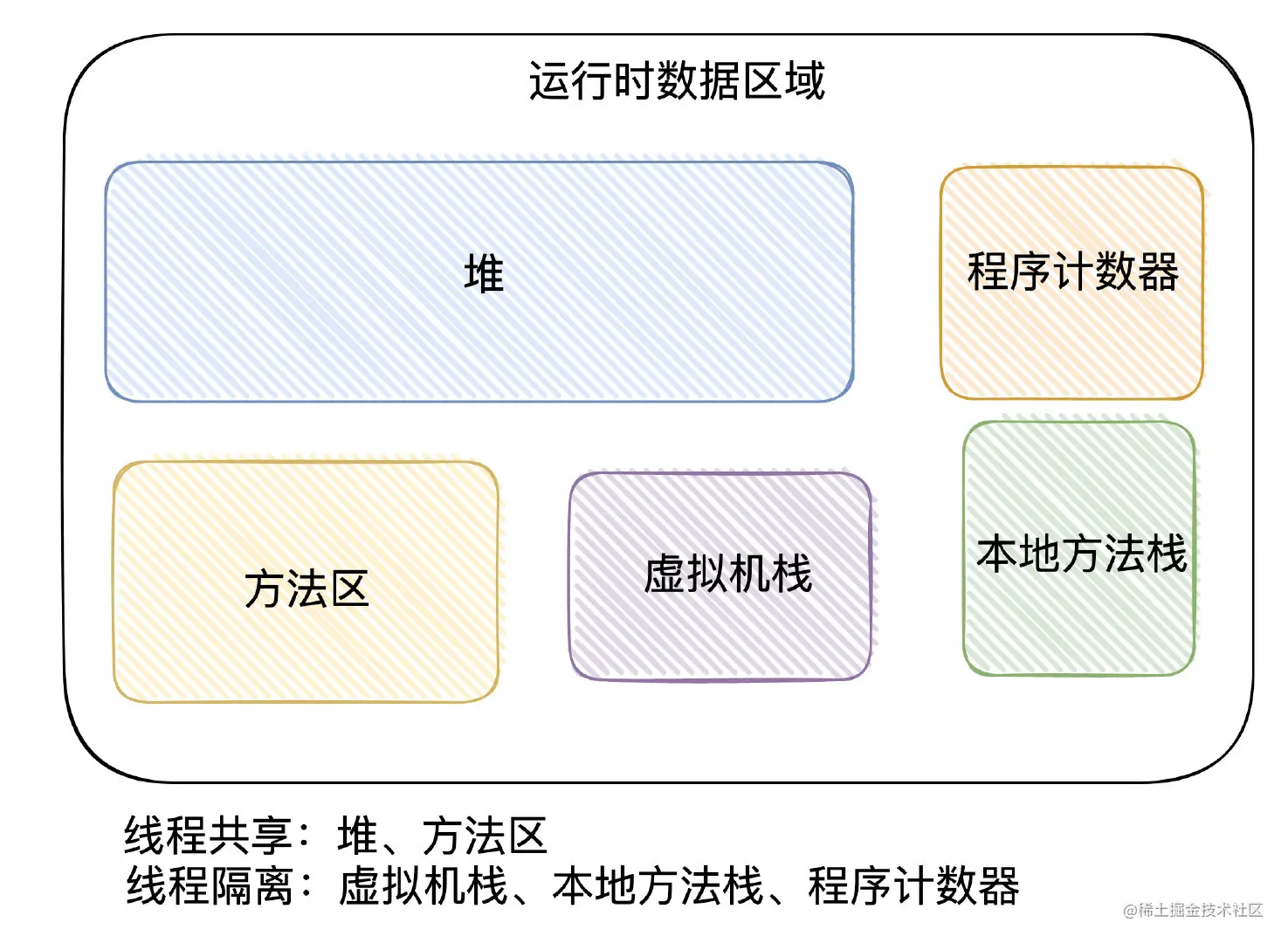
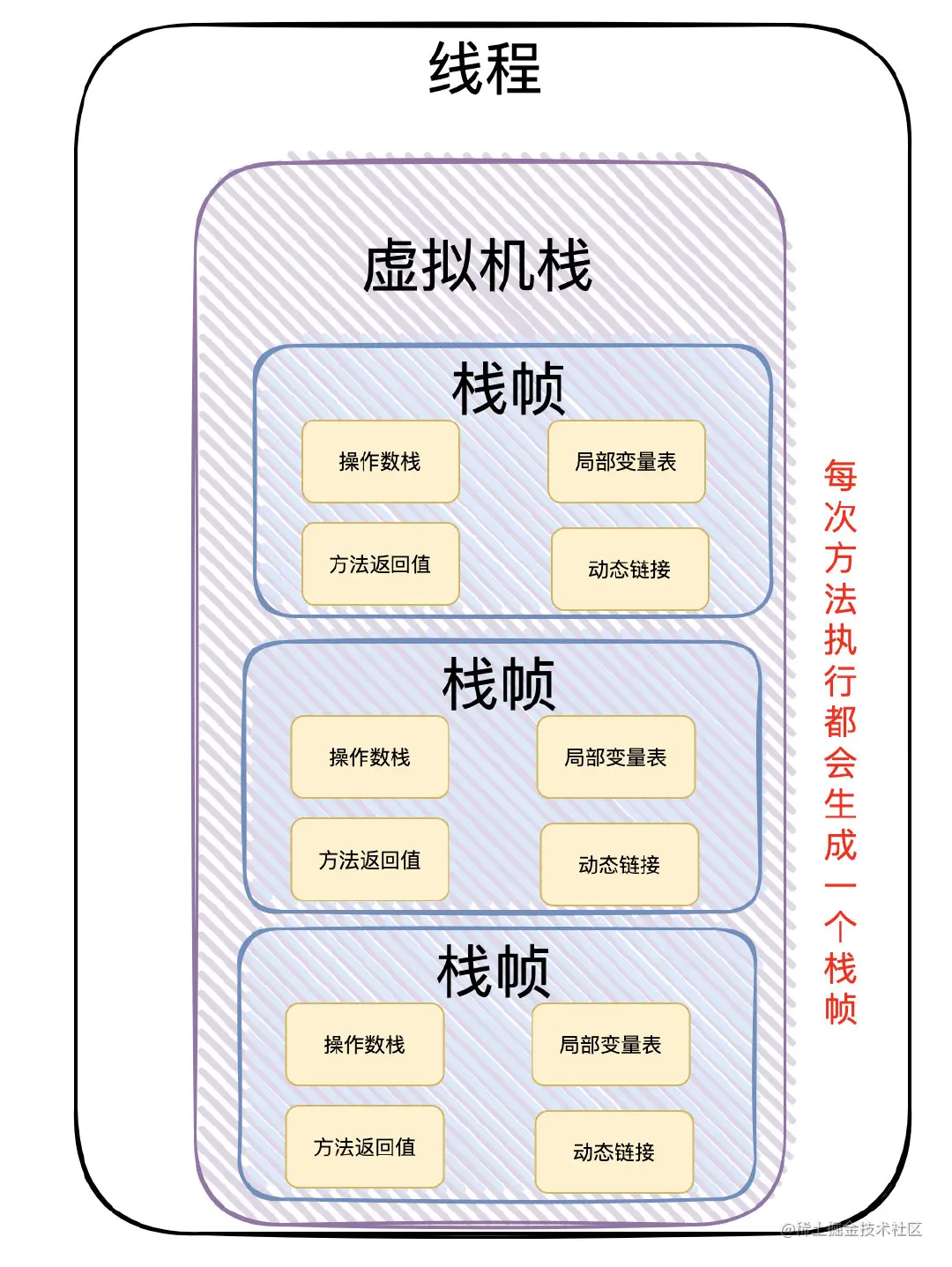
2、栈帧
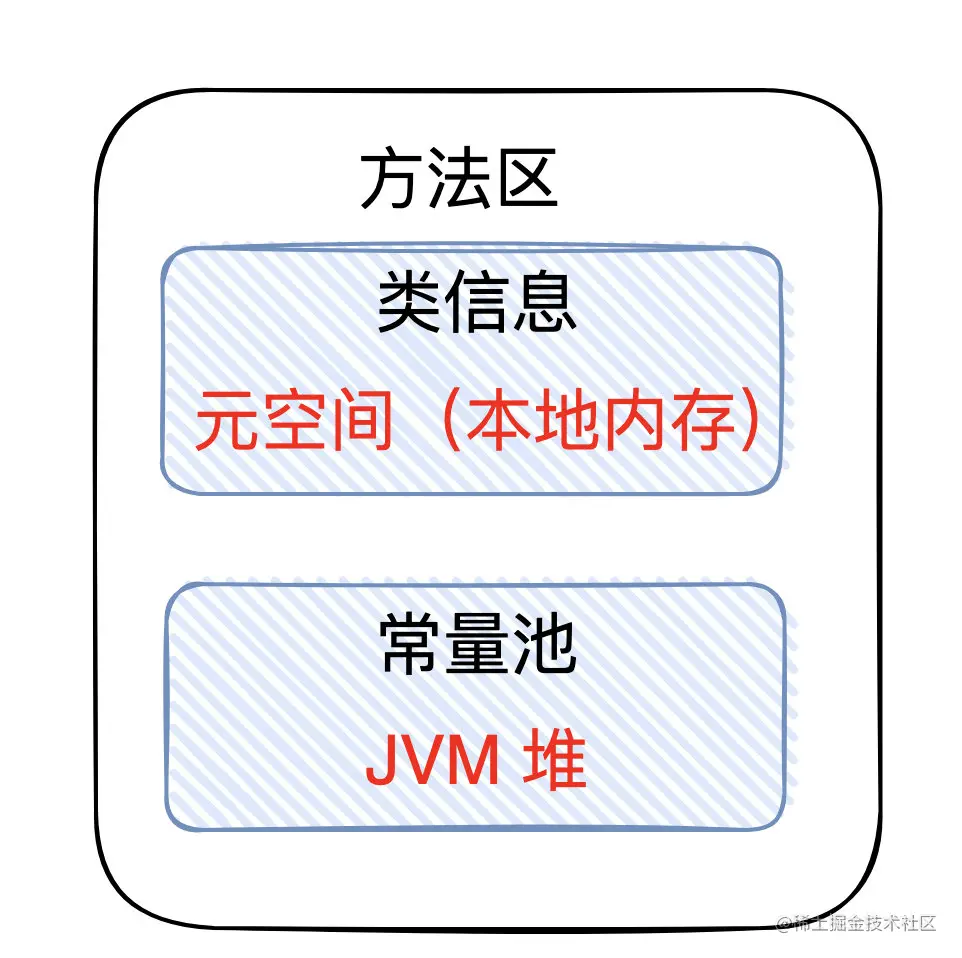
3、方法区
4、堆
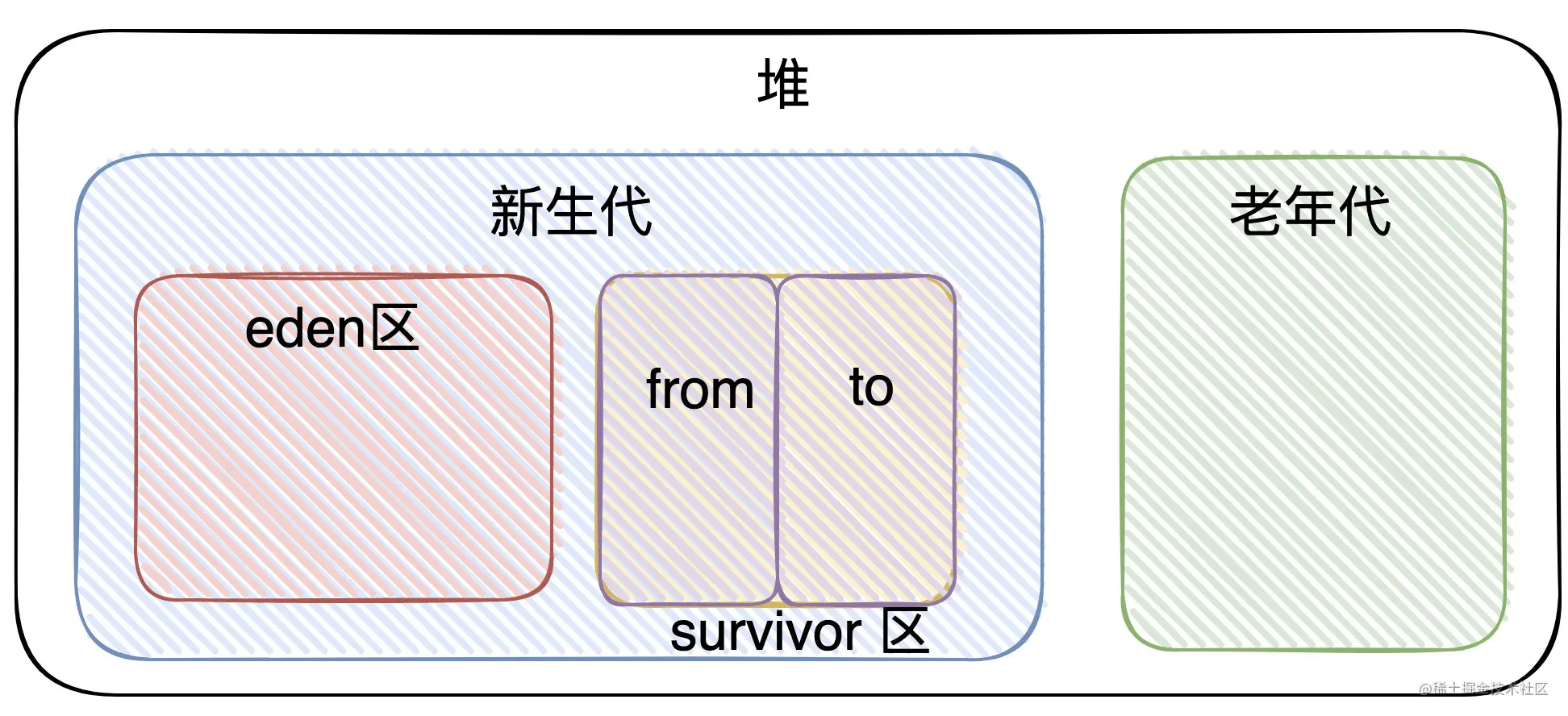
1、对象优先在Eden分配
大多数情况下,对象在新生代Eden区中分配,当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC
2、大对象直接进入老年代
所谓的大对象就是指,需要大量连续内存空间的java对象,最典型的大对象就是那种很长的字符串及数组。
3、长期存活的对象将直接进入老年代
4、Eden与Survior区默认 8:1:1
5、分配流程
1、引用计数法
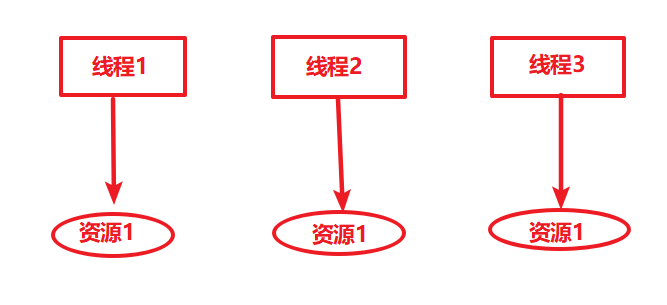
这个算法简单效率高,就是给对象添加一个引用计数器,当一个地方引用它时就加1,当引用失效时减一,当计数器的值为0时就表明这个对象不会被使用成为了无用对象,可被回收。这种算法虽然简单,但有一个致命问题:无法解决相互引用的问题。
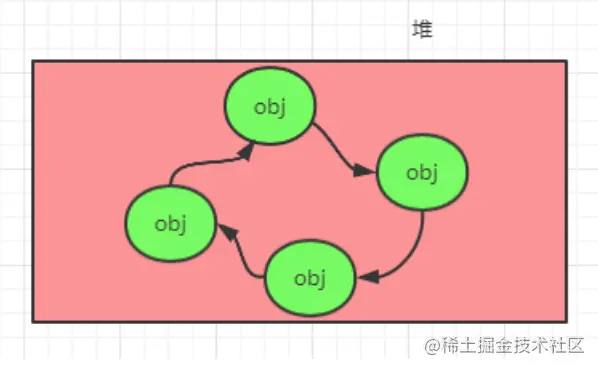
上面四个对象相互引用,但是并没有其他对象引用它们,这种对象实际上也是无效对象,但是通过引用计数法它们的计数器的值为1无法被回收。
2、可达性分析法
可达性分析法就是选择一些称为GC Roots的对象作为起始点,然后从GC Roots开始向下搜索,搜索路径称为引用链,当一个对象不在任何一条引用链上时,就说明此对象是无效对象,可以被回收。可达性分析法解决了引用计数法的对象间相互引用的问题。
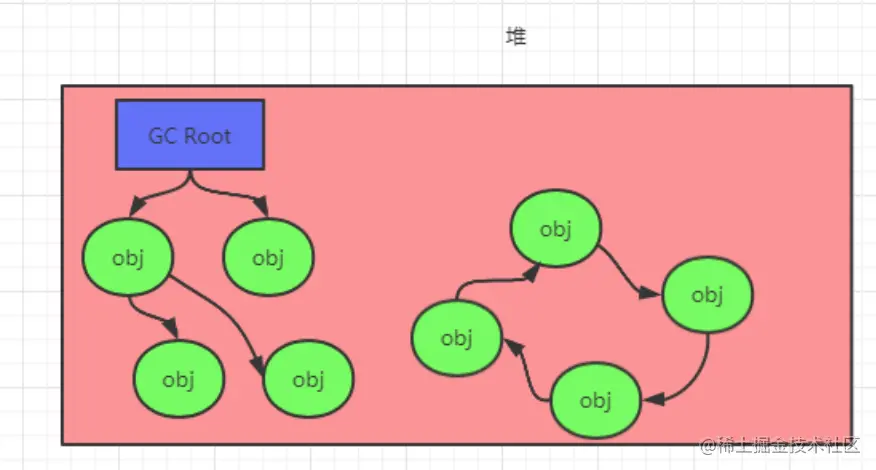
哪些对象可以作为GC Roots呢
- Java虚拟机栈内栈帧中的局部变量表中的变量
- 方法区中类静态属性
- 方法区中的常量
- 本地方法栈JNI(即Native方法)中的变量
1、强引用
我们写的代码一般都是强引用,如Object obj = new Object()这种就属于强引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
2、软引用
软引用是用来描述一些有用但并不是必需的对象,在Java中用java.lang.ref.SoftReference类来表示。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象。因此,这一点可以很好地用来解决OOM的问题,并且这个特性很适合用来实现缓存:比如网页缓存、图片缓存等。
public class Main {
public static void main(String[] args) {
SoftReference<String> sr = new SoftReference<String>( new String( "hello" ));
System.out.println(sr.get());
}
}
3、弱引用
public class Main {
public static void main(String[] args) {
WeakReference<String> sr = new WeakReference<String>( new String( "hello" ));
System.out.println(sr.get());
System.gc(); //通知JVM的gc进行垃圾回收
System.out.println(sr.get());
}
}
4、虚引用
虚引用通过PhantomReference实现,称为幽灵引用或幻影引用,最弱的一种引用,一个对象是否有虚引用对其生存时间没有影响,也无法通过虚引用来取得一个对象实例。
使用虚引用的目的就是为了得知对象被GC的时机,所以可以利用虚引用来进行销毁前的一些操作,比如说资源释放等。这个虚引用对于对象而言完全是无感知的,有没有完全一样,但是对于虚引用的使用者而言,就像是待观察的对象的把脉线,可以通过它来观察对象是否已经被回收,从而进行相应的处理。
七、垃圾回收算法
1、标记-清除
被誉为现代垃圾回收算法的思想基础。
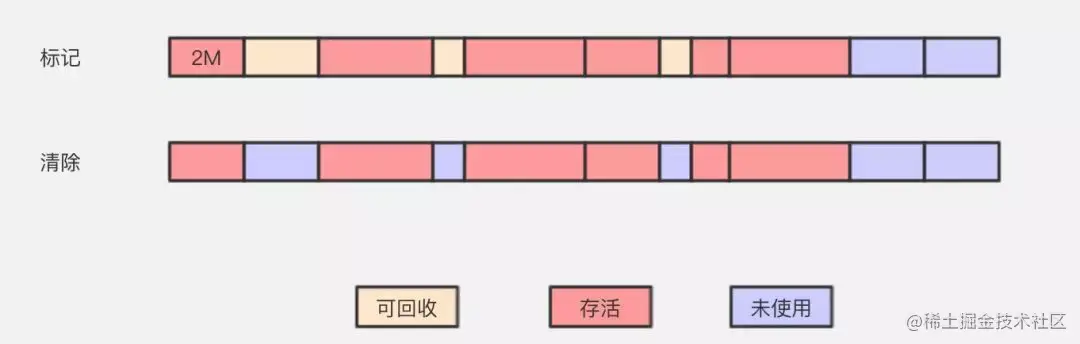
标记-清除算法采用从根集合进行扫描,对存活的对象对象标记,标记完毕后,再扫描整个空间中未被标记的对象,进行回收,如上图所示。标记-清除算法不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活对象比较多的情况下极为高效,但由于标记-清除算法直接回收不存活的对象,因此会造成内存碎片。
2、复制算法
该算法的提出是为了克服句柄的开销和解决堆碎片的垃圾回收。建立在存活对象少,垃圾对象多的前提下。此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去后还能进行相应的内存整理,不会出现碎片问题。但缺点也是很明显,就是需要两倍内存空间。
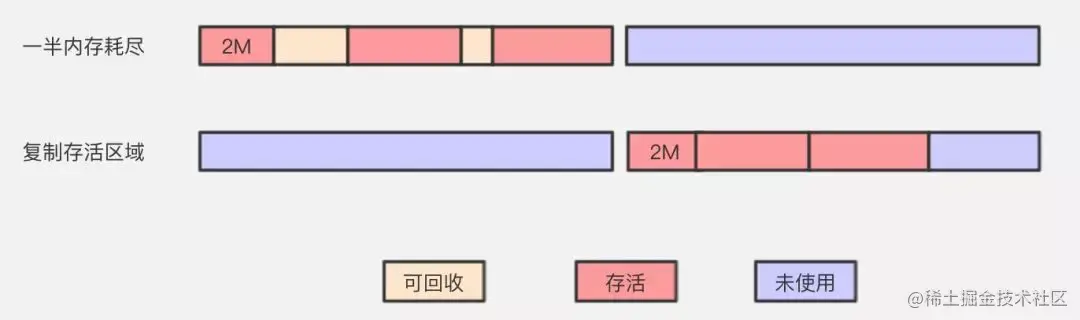
它开始时把堆分成 一个对象面和多个空闲面, 程序从对象面为对象分配空间,当对象满了,基于copying算法的垃圾 收集就从根集中扫描活动对象,并将每个活动对象复制到空闲面(使得活动对象所占的内存之间没有空闲洞),这样空闲面变成了对象面,原来的对象面变成了空闲面,程序会在新的对象面中分配内存。一种典型的基于coping算法的垃圾回收是stop-and-copy算法,它将堆分成对象面和空闲区域面,在对象面与空闲区域面的切换过程中,程序暂停执行。
3、标记整理
此算法是结合了“标记-清除”和“复制算法”两个算法的优点。避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
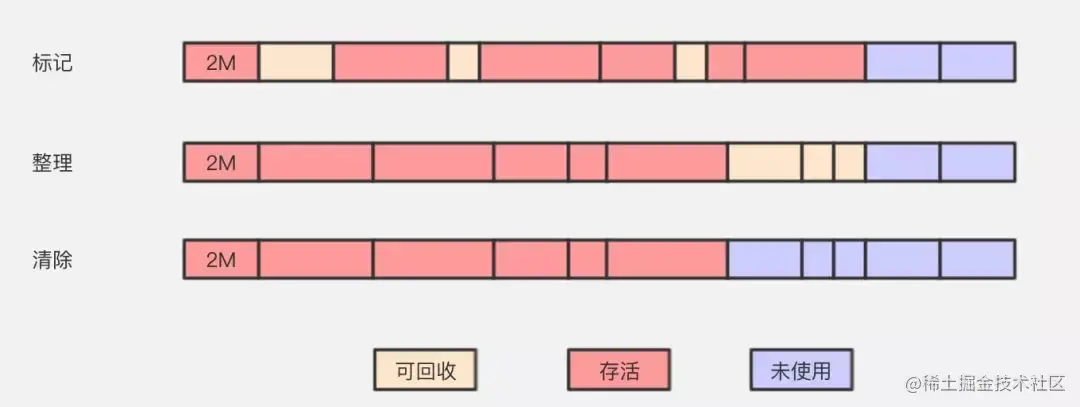
标记-整理算法采用标记-清除算法一样的方式进行对象的标记,但在清除时不同,在回收不存活的对象占用的空间后,会将所有的存活对象往左端空闲空间移动,并更新对应的指针。标记-整理算法是在标记-清除算法的基础上,又进行了对象的移动,因此成本更高,但是却解决了内存碎片的问题。在基于Compacting算法的收集器的实现中,一般增加句柄和句柄表。
4、分代回收策略
基于这样的事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的回收算法,以便提高回收效率。
新生代由于其对象存活时间短,且需要经常gc,因此采用效率较高的复制算法,其将内存区分为一个eden区和两个suvivor区,默认eden区和survivor区的比例是8:1,分配内存时先分配eden区,当eden区满时,使用复制算法进行gc,将存活对象复制到一个survivor区,当一个survivor区满时,将其存活对象复制到另一个区中,当对象存活时间大于某一阈值时,将其放入老年代。老年代和永久代因为其存活对象时间长,因此使用标记清除或标记整理算法
七、垃圾回收器
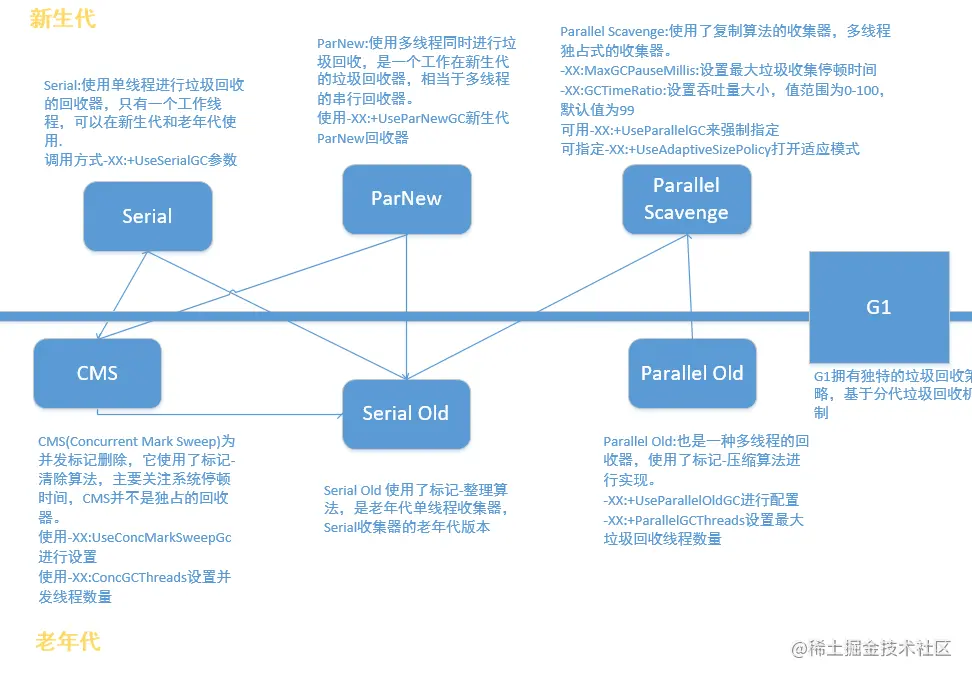
- Serial old和新生代的所有回收器都能搭配;也可以作为CMS回收器的备用回收器;
- CMS只能和新生代的Serial和ParNew搭配,而且ParNew是CMS默认的新生代回收器;
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态
- 并发(Concurrent):指用户线程和垃圾收集线程同时执行(但不一定是并行的,可能是交替执行),用户程序继续运行,而垃圾收集程序运行在另外的CPU上。
1、概念
G1的堆内存被划分为多个大小相等的 Region ,但是 Region 的总个数在 2048 个左右,默认是 2048 。对于一个 Region 来说,是逻辑连续的一段空间,其大小的取值范围是 1MB 到 32MB 之间。
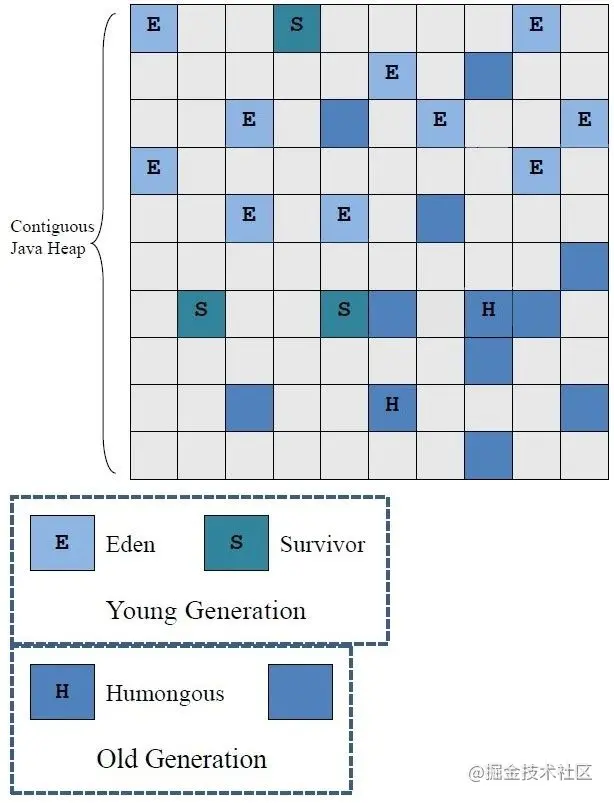
H是以往的垃圾收集器中没有的概念,它代表 Humongous,这表示这些 Region 存储的是巨型对象(humongous object,H-obj),当新建对象大小超过 Region 大小一半时,直接在新的一个或多个连续 Region 中分配,并标记为H。
2、垃圾收集
G1保留了YGC并加上了一种全新的MIXGC用于收集老年代。G1中没有Full GC,G1中的Full GC是采用serial old Full GC。
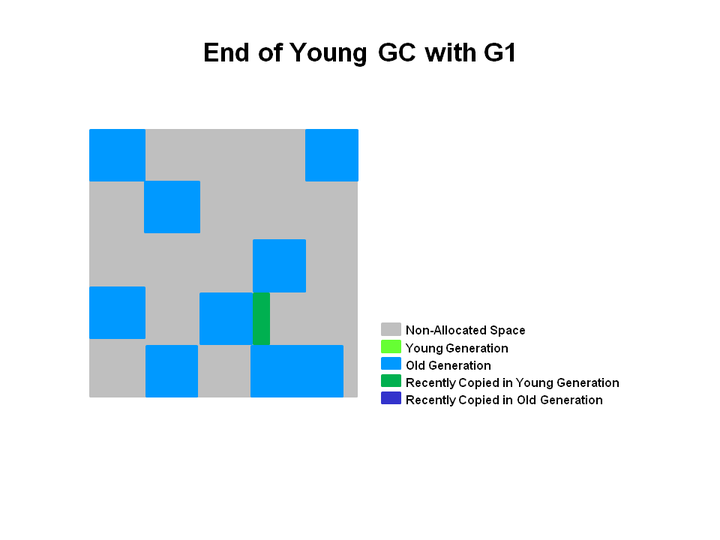
2.1 YGC
当Eden空间被占满之后,就会触发YGC。在G1中YGC依然采用复制存活对象到survivor空间的方式,当对象的存活年龄满足晋升条件时,把对象提升到old generation regions(老年代)。
G1控制YGC开销的手段是动态改变young region的个数,YGC的过程中依然会STW(stop the world 应用停顿),并采用多线程并发复制对象,减少GC停顿时间。

2.2 MIXGC
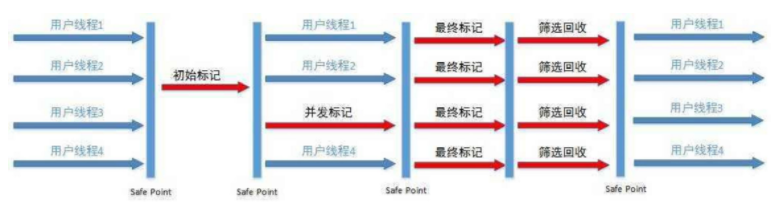
2.2.1 初始标记
这个阶段是STW(Stop the World )的,所有应用线程会被暂停,标记出从GC Root开始直接可达的对象。
2.2.2 并发标记
从GC Roots开始对堆中对象进行可达性分析,找出存活对象,耗时较长。当并发标记完成后,开始最终标记(Final Marking )阶段
2.2.3 最终标记
标记那些在并发标记阶段发生变化的对象,将被回收
2.2.4 回收
首先对各个Regin的回收价值和成本进行排序,根据用户所期待的GC停顿时间指定回收计划,回收一部分Region
父类的引用指向子类的对象(或子类的对象赋给父类的引用)
- 继承
- 重写
- 父类引用指向子类对象
成员变量,静态方法,看左边;
非静态方法:编译看左边,运行看右边
方法重载(Overload)、方法重写(Override)
重载是编译时多态,重写是运行时多态
根据里氏代换原则:任何基类可以出现的地方,子类一定可以出现。
可在函数接收的参数里面定义基类形式,提高扩展性
一、考虑用静态工厂方法代替构造器
1、我们创建对象的方式经常使用的是以下两种
方法1: 使用类公有的构造器new一个。
方法2:将构造器私有化,使用类的静态方法封装并返回一个实例。
2、用静态方法创建对象的优点
优点1: 静态工厂方法可以自由命名,根据实例的作用或者参数,赋予不同命名;而构造方法必须与类同名
Test test = new Test(int t);
Test test1 = Test.newInstance();
优点2:通过构造方法创建对象的时候,每次都要new一个新对象。而通过静态方法,可以选择每次采用单例模式来复用对象,这对于一个性能要求高的系统,可以显著提高运行速度。
public class DoubleCheckSingleton {
private volatile static DoubleCheckSingleton singleton;
private DoubleCheckSingleton() {
}
public static DoubleCheckSingleton getSingleton() {
if (singleton == null) {
synchronized (DoubleCheckSingleton.class) {
if (singleton == null) {
singleton = new DoubleCheckSingleton();
}
}
}
return singleton;
}
}
优点3: 静态工厂方法可以根据要求返回返回任何子类型的对象,我们可以灵活的创建对象
public class ClothesA {
private ClothesA(){
}
protected static ClothesA makeClothes(String type){
ClothesA clothes;
switch (type) {
case "spring":
clothes = new Shirt();
break;
case "winter":
clothes = new Sweater();
break;
case "summer":
clothes = new Cotta();
break;
default:
clothes = null;
break;
}
return clothes;
}
static class Shirt extends ClothesA{
public Shirt(){
System.out.println("制作一件衬衣");
}
}
static class Sweater extends ClothesA{
public Sweater(){
System.out.println("制作一件毛衣");
}
}
static class Cotta extends ClothesA{
public Cotta(){
System.out.println("制作一件短袖");
}
}
}
二、遇到多个构造器参数时要考虑使用构建器
//Builder Pattern
public class NutritionFacts{
private final int servingSize;
private final int servings;
private final int calories;
private final int fat;
private final int sodium;
private final int carbohydrate;
public static class Buider{
//Required parameters
private final int servingSize;
private final int servings;
// Optional parameters - initialized to default values
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public Builder(int servingSize,int servings){
this.servingSize=servingSize;
this.servings=servings;
}
public Builder calories(int val)
{calories=val;return this;}
public Builder fat(int val)
{fat=val;return this;}
public Builder sodium(int val)
{sodium=val;return this;}
public Builder carbohydrate(int val)
{carbohydrate= val;return this;}
public NutritionFacts build(){
return new NutritionFacts(this);
}
}
private NutritionFacts(Builder builder){
servingSize=builder.servingSize;
servings=builder.servings;
calories=builder.calories;
fat=builder.fat;
sodium=builder.sodium;
carbohydrate=builder.carbohydrate;
}
}
NutritionFacts cocaCola=new NutritionFacts.Builder(240,8).calories(100).sodium(35).carbohydrate(27).build();
三、try-with-resources 优先于 try-finally
private void correctWriting() throws IOException {
DataOutputStream out = null;
try {
out = new DataOutputStream(new FileOutputStream("data"));
out.writeInt(666);
out.writeUTF("Hello");
} finally {
if (out != null) {
out.close();
}
}
}
使用try-with-resources后
private void writingWithARM() throws IOException {
try (DataOutputStream out
= new DataOutputStream(new FileOutputStream("data"))) {
out.writeInt(666);
out.writeUTF("Hello");
}
}
新结构扩展了 try 块,按照与 for 循环相似的方式声明了资源。在 try 块中声明打开的任何资源都会关闭。
四、覆盖 equals 时总要覆盖 hashCode

五、始终要覆盖 toString