《Focal Loss for Dense Object Detection》 :RetinaNet
[TOC]
作者:2018年Facebook AI团队,Tsung-Yi Lin,Ross Girshick与Kaiming He等。
本文主要内容:标题意为:Focal Loss在目标检测上的应用,关注了正负样本失衡的问题。Focal结合了ResNet+FPN,网络几乎没改,改的是分类loss。Focal Loss是交叉熵loss的变体。
双阶段检测准确但是速度慢,单阶段可以实时检测但是准确度低。双阶段如Fast R-CNN虽然先用RPN对anchors进行二分类,经过NMS和TOP_N等,但是仅仅是从何“类别极不平衡”到“类别较不平衡”转变,没有根本性解决问题。而单阶段检测。负样本太多且信息量很少但支配着loss,影响了训练。常规解决方法是负样本挖掘,使正负样本维持一定的比率用于训练。
一张图中候选框秘密麻麻,却只有少量gt物体,这样正负样本会带来如下影响:
(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models.
解释:负样本太多且易分类,占loss的大部分,使得训练优化方向低效。
先前也有一些算法来处理类别不均衡的问题,比如
OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM算法忽略了容易分类的样本,而是通过一次前向过程算出loss后只选择那些loss大的进行反向传播。这么做的缘由是认为。负样本中的大多数是easy example,而困难样本hard example可能包含了不容易区分的背景类物体,跟gt有部分重叠。这样的话即使正负样本按比例采用,也会因为负样本都是易分类样本而负样本的loss很小,这样训练很不高效,且会主导网络的训练过程,而实际中我们应该更关注那些困难样本。
OHEM即采用了难样本进行训练,因为loss大。而Focal loss的想法是让难分类样本的loss权重大些,同时还关注了类别不平衡问题。
-
我们原来的交叉熵的形式是这样的:CE(cross-entropy) loss
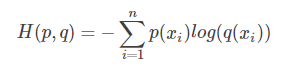
只不过当2分类的时候,比如是前景,那么前景的$p1*$为1,其余$Pi*$为0,所以最后只剩下了前景的$log_{p前景}$。同理而当时背景时$p2*$为1,其余$Pi*$为0,所以最后只剩下了背景的$log_{p背景}$。所以从约去0项的结果来看,loss最后即下式(1)。但在这篇论文中式(1)反倒阻碍了我们理解focal loss,反而理解原来形式的交叉熵更能理解好这个pt是怎么来的,说到底这个pt就是每个类别的概率,而不是之前的单一的前景的概率。
同时我还思考过loss函数是分段函数的话会不会造成反向传播不可导?我的理解是:这个还是还不算是传统意义上的分段函数。传统的分段函数是比如f=|x-0.5|(本来想距离绝对值x,但是绝对值x在大于0的时候是可导的),如果在考虑一个样本的时候,此时这个样本的gt是确定的(有的loss也可能与gt没关系),所以这个样本对应的loss就是|x-0.5|,显然这个函数不能梯度回传,因为在x=0.5处不可求导。但是在这篇文中,loss并不是那样分段的,而是一旦给定了一个样本,他的gt的值y是确定的,所以loss函数此时确定了,但是确定的函数并不是分段函数,而是简单的-logp。或者说可以理解为条件概率函数。

好了,我们现在认为对于给定的一个样本,其gt值为y,他的loss就是$-log_{p_t}$,其中pt是对于类y的概率。
Focal loss第一个改动的地方是让对于给定的一个样本,虽然我们还是算其交叉熵-logpt,但是在此前面加了个alpha_t,即$-\alpha t log{p_t}$,其中alpha_t重点关注的是t,这代表和pt一样,是对应于每个类y而言的。这样我们就可以比如让苹果loss权重大些,香蕉的loss权重小些,这样起到了调节各个分类loss的作用。而应用到检测中,通过实验,选择了让正例前景loss的权重为0.25,而背景权重loss权重为0.75时为最佳。(文中让alpha为前景的权重,而1-alpha为背景的权重,即alpha=0.25)。刚开始看到0.25是作用在前景上时,我也思考了一番,为什么不是背景权重为0.25,难道我们不应该更注重前景的提取吗?我骗自己的理解是区分出来背景中含一些物体这样的anchor更重要(loss也更大)。
我们让loss更专注于难分样本,即如果样本越难分类,那么越给更大的权重,让模型更侧重学习如何分类这些样本;给易分样本小权重。拿什么分辨难易程度?既然我们之前说了对于类别y的一个样本交叉熵为-logpt,那么如果pt接近于1,即代表预测的很好,gt为这个类别,而模型又预测这个样本更可能属于这个类别,即代表这个样本对于模型来说是易分辨的。即pt越大,代表易样本;pt越小,代表难样本。我们用(1-pt)即可简单地为其加上权重,即pt越小,权重越大。而实际中,还可以使用$FL(p_t)=-(1-p_t)^r log p_t$作为loss函数。
结合上面两个不同的权重,即变成了$FL(p_t)=-\alpha_t(1-p_t)^r log p_t$。实验表明α取0.25,γ取2效果最好。(对于负类取的是0.75)
一般我们初始化CNN网络模型时都会使用无偏的参数对其初始化,比如Conv的kernel 参数我们会以bias 为0,variance为0.01的某分布来对其初始化。但是如果我们的模型要去处理类别极度不平衡的情况,那么就会考虑到这样对训练数据分布无任选先验假设的初始化会使得在训练过程中,我们的参数更偏向于拥有更多数量的负样本的情况去进化。作者观察下来发现它在训练时会出现极度的不稳定。于是作者在初始化模型最后一层参数时考虑了数据样本分布的不平衡性,这样使得初始训练时最终得出的loss不会对过多的负样本数量所惊讶到,从而有效地规避了初始训练时模型的震荡与不稳定。
RetinaNet本质上是Resnet + FPN + 两个FCN子网络。 以下为RetinaNet目标框架框架图。有了之前blog里面提到的FPN与FCN的知识后,我们很容易理解此框架的设计含义。

RetinaNet目标检测框架
一般主干网络可选用任一有效的特征提取网络如vgg16或resnet系列,此处作者分别尝试了resnet-50与resnet-101。而FPN则是对resnet-50里面自动形成的多尺度特征进行了强化利用,从而得到了表达力更强、包含多尺度目标区域信息的feature maps集合。最后在FPN所吐出的feature maps集合上,分别使用了两个FCN子网络(它们有着相同的网络结构却各自独立,并不share参数)用来完成目标框类别分类与位置回归任务。
- 模型推理
一旦我们有了训练好的模型,在正式部署时,只需对其作一次forward,然后对最终生成的目标区域进行过渡。然后只对每个FPN level上目标存在概率最高的前1000个目标框进一步地decoding处理。接下来再将所有FPN level上得到的目标框汇集起来,统一使用极大值抑制的方法进一步过渡(其中极大值抑制时所用的阈值为0.5)。这样,我们就得到了最终的目标与其位置框架。
- 模型训练
模型训练中主要在后端Loss计算时采用了Focal loss,另外也在模型初始化时考虑到了正负样本极度不平衡的情况进而对模型最后一个conv layer的bias参数作了有偏初始化。
训练时用了SGD,mini batch size为16,在8个GPU上一块训练,每个GPU上local batch size为2。最大iterations数目为90,000;模型初始lr为0.01,接下来随着训练进行分step wisely 降低。真正的training loss则为表达目标类别的focus loss与表达目标框位置回归信息的L1 loss的和。
下图为RetinaNet模型的检测准度与性能。

RetinaNet的检测准度与性能
retinanet的主网络部分结构并不与FPN中提到的结构完全一致,retinanet使用特征金字塔层P3,P4,P5,P6,P7,其中,P3,P4,P5与FPN中的产生方式一样,通过上采样和横向连接从C3,C4,C5中产生,P6是在C5的基础上通过3x3的卷积核,步长为2的卷积得到的,P7在P6的基础上加了个RELU再通过3x3的卷积核,步长为2的卷积得到的。这部分的kreas代码如下:
def __create_pyramid_features(C3, C4, C5, feature_size=256):
""" Creates the FPN layers on top of the backbone features.
Args
C3 : Feature stage C3 from the backbone.
C4 : Feature stage C4 from the backbone.
C5 : Feature stage C5 from the backbone.
feature_size : The feature size to use for the resulting feature levels.
Returns
A list of feature levels [P3, P4, P5, P6, P7].
"""
# upsample C5 to get P5 from the FPN paper
P5 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C5_reduced')(C5) # P 5由C5上1×1卷积而来
P5_upsampled = layers.UpsampleLike(name='P5_upsampled')([P5, C4]) # 上采样,C4是用来量shape的
P5 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P5')(P5) # P5还会经过一个3×3卷积
# add P5 elementwise to C4
P4 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C4_reduced')(C4)
P4 = keras.layers.Add(name='P4_merged')([P5_upsampled, P4])
P4_upsampled = layers.UpsampleLike(name='P4_upsampled')([P4, C3])
P4 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P4')(P4)
# add P4 elementwise to C3
P3 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C3_reduced')(C3)
P3 = keras.layers.Add(name='P3_merged')([P4_upsampled, P3])
P3 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P3')(P3)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
P6 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P6')(C5) # P6是C5上3×3卷积,步长为2得来的
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
P7 = keras.layers.Activation('relu', name='C6_relu')(P6)
P7 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P7')(P7) # P7是P6上先relu,然后3×3,步长为2的卷积
return [P3, P4, P5, P6, P7]以下函数用于从FPN的各个level的feature maps上提取各种scale的anchor box。
def _create_cell_anchors():
"""
Generate all types of anchors for all fpn levels/scales/aspect ratios.
This function is called only once at the beginning of inference.
"""
k_max, k_min = cfg.FPN.RPN_MAX_LEVEL, cfg.FPN.RPN_MIN_LEVEL
scales_per_octave = cfg.RETINANET.SCALES_PER_OCTAVE
aspect_ratios = cfg.RETINANET.ASPECT_RATIOS
anchor_scale = cfg.RETINANET.ANCHOR_SCALE
A = scales_per_octave * len(aspect_ratios)
anchors = {}
for lvl in range(k_min, k_max + 1):
# create cell anchors array
stride = 2. ** lvl
cell_anchors = np.zeros((A, 4))
a = 0
for octave in range(scales_per_octave):
octave_scale = 2 ** (octave / float(scales_per_octave))
for aspect in aspect_ratios:
anchor_sizes = (stride * octave_scale * anchor_scale, )
anchor_aspect_ratios = (aspect, )
cell_anchors[a, :] = generate_anchors(
stride=stride, sizes=anchor_sizes,
aspect_ratios=anchor_aspect_ratios)
a += 1
anchors[lvl] = cell_anchors
return anchors下面函数则描述了如何使用train好的RetinaNet来进行图片目标检测。
def im_detect_bbox(model, im, timers=None):
"""Generate RetinaNet detections on a single image."""
if timers is None:
timers = defaultdict(Timer)
# Although anchors are input independent and could be precomputed,
# recomputing them per image only brings a small overhead
anchors = _create_cell_anchors()
timers['im_detect_bbox'].tic()
k_max, k_min = cfg.FPN.RPN_MAX_LEVEL, cfg.FPN.RPN_MIN_LEVEL
A = cfg.RETINANET.SCALES_PER_OCTAVE * len(cfg.RETINANET.ASPECT_RATIOS)
inputs = {}
inputs['data'], im_scale, inputs['im_info'] = \
blob_utils.get_image_blob(im, cfg.TEST.SCALE, cfg.TEST.MAX_SIZE)
cls_probs, box_preds = [], []
for lvl in range(k_min, k_max + 1):
suffix = 'fpn{}'.format(lvl)
cls_probs.append(core.ScopedName('retnet_cls_prob_{}'.format(suffix)))
box_preds.append(core.ScopedName('retnet_bbox_pred_{}'.format(suffix)))
for k, v in inputs.items():
workspace.FeedBlob(core.ScopedName(k), v.astype(np.float32, copy=False))
workspace.RunNet(model.net.Proto().name)
cls_probs = workspace.FetchBlobs(cls_probs)
box_preds = workspace.FetchBlobs(box_preds)
# here the boxes_all are [x0, y0, x1, y1, score]
boxes_all = defaultdict(list)
cnt = 0
for lvl in range(k_min, k_max + 1):
# create cell anchors array
stride = 2. ** lvl
cell_anchors = anchors[lvl]
# fetch per level probability
cls_prob = cls_probs[cnt]
box_pred = box_preds[cnt]
cls_prob = cls_prob.reshape((
cls_prob.shape[0], A, int(cls_prob.shape[1] / A),
cls_prob.shape[2], cls_prob.shape[3]))
box_pred = box_pred.reshape((
box_pred.shape[0], A, 4, box_pred.shape[2], box_pred.shape[3]))
cnt += 1
if cfg.RETINANET.SOFTMAX:
cls_prob = cls_prob[:, :, 1::, :, :]
cls_prob_ravel = cls_prob.ravel()
# In some cases [especially for very small img sizes], it's possible that
# candidate_ind is empty if we impose threshold 0.05 at all levels. This
# will lead to errors since no detections are found for this image. Hence,
# for lvl 7 which has small spatial resolution, we take the threshold 0.0
th = cfg.RETINANET.INFERENCE_TH if lvl < k_max else 0.0
candidate_inds = np.where(cls_prob_ravel > th)[0]
if (len(candidate_inds) == 0):
continue
pre_nms_topn = min(cfg.RETINANET.PRE_NMS_TOP_N, len(candidate_inds))
inds = np.argpartition(
cls_prob_ravel[candidate_inds], -pre_nms_topn)[-pre_nms_topn:]
inds = candidate_inds[inds]
inds_5d = np.array(np.unravel_index(inds, cls_prob.shape)).transpose()
classes = inds_5d[:, 2]
anchor_ids, y, x = inds_5d[:, 1], inds_5d[:, 3], inds_5d[:, 4]
scores = cls_prob[:, anchor_ids, classes, y, x]
boxes = np.column_stack((x, y, x, y)).astype(dtype=np.float32)
boxes *= stride
boxes += cell_anchors[anchor_ids, :]
if not cfg.RETINANET.CLASS_SPECIFIC_BBOX:
box_deltas = box_pred[0, anchor_ids, :, y, x]
else:
box_cls_inds = classes * 4
box_deltas = np.vstack(
[box_pred[0, ind:ind + 4, yi, xi]
for ind, yi, xi in zip(box_cls_inds, y, x)]
)
pred_boxes = (
box_utils.bbox_transform(boxes, box_deltas)
if cfg.TEST.BBOX_REG else boxes)
pred_boxes /= im_scale
pred_boxes = box_utils.clip_tiled_boxes(pred_boxes, im.shape)
box_scores = np.zeros((pred_boxes.shape[0], 5))
box_scores[:, 0:4] = pred_boxes
box_scores[:, 4] = scores
for cls in range(1, cfg.MODEL.NUM_CLASSES):
inds = np.where(classes == cls - 1)[0]
if len(inds) > 0:
boxes_all[cls].extend(box_scores[inds, :])
timers['im_detect_bbox'].toc()
# Combine predictions across all levels and retain the top scoring by class
timers['misc_bbox'].tic()
detections = []
for cls, boxes in boxes_all.items():
cls_dets = np.vstack(boxes).astype(dtype=np.float32)
# do class specific nms here
keep = box_utils.nms(cls_dets, cfg.TEST.NMS)
cls_dets = cls_dets[keep, :]
out = np.zeros((len(keep), 6))
out[:, 0:5] = cls_dets
out[:, 5].fill(cls)
detections.append(out)
# detections (N, 6) format:
# detections[:, :4] - boxes
# detections[:, 4] - scores
# detections[:, 5] - classes
detections = np.vstack(detections)
# sort all again
inds = np.argsort(-detections[:, 4])
detections = detections[inds[0:cfg.TEST.DETECTIONS_PER_IM], :]
# Convert the detections to image cls_ format (see core/test_engine.py)
num_classes = cfg.MODEL.NUM_CLASSES
cls_boxes = [[] for _ in range(cfg.MODEL.NUM_CLASSES)]
for c in range(1, num_classes):
inds = np.where(detections[:, 5] == c)[0]
cls_boxes[c] = detections[inds, :5]
timers['misc_bbox'].toc()
return cls_boxes以下为RetinaNet中training loss的具体计算。可以看出它包含了两个部分分别为反映位置信息的L1 loss与反映类别信息的focus loss。
def add_fpn_retinanet_losses(model):
loss_gradients = {}
gradients, losses = [], []
k_max = cfg.FPN.RPN_MAX_LEVEL # coarsest level of pyramid
k_min = cfg.FPN.RPN_MIN_LEVEL # finest level of pyramid
model.AddMetrics(['retnet_fg_num', 'retnet_bg_num'])
# ==========================================================================
# bbox regression loss - SelectSmoothL1Loss for multiple anchors at a location
# ==========================================================================
for lvl in range(k_min, k_max + 1):
suffix = 'fpn{}'.format(lvl)
bbox_loss = model.net.SelectSmoothL1Loss(
[
'retnet_bbox_pred_' + suffix,
'retnet_roi_bbox_targets_' + suffix,
'retnet_roi_fg_bbox_locs_' + suffix, 'retnet_fg_num'
],
'retnet_loss_bbox_' + suffix,
beta=cfg.RETINANET.BBOX_REG_BETA,
scale=model.GetLossScale() * cfg.RETINANET.BBOX_REG_WEIGHT
)
gradients.append(bbox_loss)
losses.append('retnet_loss_bbox_' + suffix)
# ==========================================================================
# cls loss - depends on softmax/sigmoid outputs
# ==========================================================================
for lvl in range(k_min, k_max + 1):
suffix = 'fpn{}'.format(lvl)
cls_lvl_logits = 'retnet_cls_pred_' + suffix
if not cfg.RETINANET.SOFTMAX:
cls_focal_loss = model.net.SigmoidFocalLoss(
[
cls_lvl_logits, 'retnet_cls_labels_' + suffix,
'retnet_fg_num'
],
['fl_{}'.format(suffix)],
gamma=cfg.RETINANET.LOSS_GAMMA,
alpha=cfg.RETINANET.LOSS_ALPHA,
scale=model.GetLossScale(),
num_classes=model.num_classes - 1
)
gradients.append(cls_focal_loss)
losses.append('fl_{}'.format(suffix))
else:
cls_focal_loss, gated_prob = model.net.SoftmaxFocalLoss(
[
cls_lvl_logits, 'retnet_cls_labels_' + suffix,
'retnet_fg_num'
],
['fl_{}'.format(suffix), 'retnet_prob_{}'.format(suffix)],
gamma=cfg.RETINANET.LOSS_GAMMA,
alpha=cfg.RETINANET.LOSS_ALPHA,
scale=model.GetLossScale(),
num_classes=model.num_classes
)
gradients.append(cls_focal_loss)
losses.append('fl_{}'.format(suffix))
loss_gradients.update(blob_utils.get_loss_gradients(model, gradients))
model.AddLosses(losses)
return loss_gradients- Focal Loss for Dense Object Detection, Tsung-Yi Lin, 2018
- https://github.com/facebookresearch/Detectron
- https://blog.csdn.net/zziahgf/article/details/83589973
- https://zhuanlan.zhihu.com/p/28527749